Tener visibilidad de su aplicación Java es crucial para entender cómo funciona ahora mismo, cómo funcionó alguna vez en el pasado, y aumentar su comprensión de cómo podría funcionar en el futuro. La mayoría de las veces, el análisis de los registros es la forma más rápida de detectar lo que ha ido mal, por lo que el registro en Java es fundamental para garantizar el rendimiento y la salud de su aplicación, así como para minimizar y reducir cualquier tiempo de inactividad. Tener una solución centralizada de registro y monitorización ayuda a reducir el Tiempo Medio de Reparación mejorando la efectividad de su equipo de Operaciones o DevOps.
Siguiendo las buenas prácticas obtendrá más valor de sus registros y hará más fácil su uso. Podrás localizar más fácilmente la causa raíz de los errores y el mal rendimiento y resolver los problemas antes de que afecten a los usuarios finales. Así que hoy, permítame compartir algunas de las mejores prácticas que debe jurar cuando se trabaja con aplicaciones Java. Vamos a profundizar.
- Utilizar una biblioteca de registro estándar
- Selecciona tus apéndices sabiamente
- Use Meaningful Messages
- Logging Java Stack Traces
- Logging Java Exceptions
- Use el nivel de registro apropiado
- Log en JSON
- Mantenga la estructura del registro consistente
- Agrega contexto a tus logs
- Java Logging in Containers
- No registres ni mucho ni poco
- Mantenga la audiencia en mente
- Evite registrar información sensible
- Usa una solución de gestión de registros para centralizar &Monitorizar los registros de Java
- Conclusión
- Compartir
Utilizar una biblioteca de registro estándar
El registro en Java se puede hacer de diferentes maneras. Usted puede utilizar una biblioteca de registro dedicado, una API común, o incluso sólo escribir registros a un archivo o directamente a un sistema de registro dedicado. Sin embargo, cuando elija la biblioteca de registro para su sistema, piense con antelación. Las cosas a considerar y evaluar son el rendimiento, la flexibilidad, los apéndices para las nuevas soluciones de centralización de registros, etc. Si te atas directamente a un único framework, el cambio a una nueva librería puede llevar una cantidad sustancial de trabajo y tiempo. Tenga esto en cuenta y opte por la API que le dará la flexibilidad de cambiar las bibliotecas de registro en el futuro. Al igual que con el cambio de Log4j a Logback y a Log4j 2, cuando se utiliza la API SLF4J lo único que hay que hacer es cambiar la dependencia, no el código.
Si eres nuevo en las bibliotecas de registro de Java, echa un vistazo a nuestras guías para principiantes:
- Tutorial de Log4j
- Tutorial de Logback
- Tutorial de Log4j2
- Tutorial de SLF4J
Selecciona tus apéndices sabiamente
Los apéndices definen dónde se entregarán tus eventos de registro. Los apéndices más comunes son los apéndices de consola y de archivo. Aunque son útiles y ampliamente conocidos, puede que no satisfagan sus necesidades. Por ejemplo, usted puede querer escribir sus registros de una manera asincrónica o puede querer enviar sus registros a través de la red utilizando apéndices como el de Syslog, así:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Sin embargo, tenga en cuenta que el uso de apéndices como el que se muestra arriba hace que su tubería de registro sea susceptible a los errores de red y a las interrupciones de comunicación. Esto puede resultar en que los registros no se envíen a su destino, lo que puede ser inaceptable. También querrá evitar que el registro afecte a su sistema si el appender está diseñado de forma bloqueante. Para aprender más revise nuestra publicación en el blog Logging libraries vs Log shippers.
Use Meaningful Messages
Una de las cosas cruciales cuando se trata de crear logs, y sin embargo una de las no tan fáciles es usar mensajes significativos. Sus eventos de registro deben incluir mensajes que sean únicos para la situación dada, describirlos claramente e informar a la persona que los lee. Imagina que se produce un error de comunicación en tu aplicación. Podrías hacerlo así:
LOGGER.warn("Communication error");
Pero también podrías crear un mensaje como este:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Puedes ver fácilmente que el primer mensaje informará a la persona que mira los registros sobre algunos problemas de comunicación. Esa persona probablemente tendrá el contexto, el nombre del registrador, y el número de línea donde ocurrió la advertencia, pero eso es todo. Para obtener más contexto, esa persona tendría que mirar el código, saber con qué versión del código está relacionado el error, etc. Esto no es divertido y a menudo no es fácil, y ciertamente no es algo que uno quiere estar haciendo al tratar de solucionar un problema de producción lo más rápido posible.
El segundo mensaje es mejor. Proporciona información exacta sobre qué tipo de error de comunicación ocurrió, qué estaba haciendo la aplicación en ese momento, qué código de error obtuvo y cuál fue la respuesta del servidor remoto. Por último, también informa de que se volverá a intentar el envío del mensaje. Trabajar con este tipo de mensajes es definitivamente más fácil y agradable.
Por último, piensa en el tamaño y la verbosidad del mensaje. No registre información demasiado verbosa. Estos datos necesitan ser almacenados en algún lugar para ser útiles. Un mensaje muy largo no será un problema, pero si esa línea se repite cientos de veces en un minuto y tienes muchos registros verbosos, mantener una retención más larga de esos datos puede ser problemático y, al final, también costará más.
Logging Java Stack Traces
Una de las partes muy importantes del logging de Java son los stack traces de Java. Echa un vistazo al siguiente código:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
El código anterior hará que se lance una excepción y un mensaje de registro que se imprimirá en la consola con nuestra configuración por defecto tendrá el siguiente aspecto:
11:42:18.952 ERROR - Error while executing main thread
Como puedes ver no hay mucha información ahí. Sólo sabemos que se ha producido el problema, pero no sabemos dónde se ha producido, ni cuál ha sido el problema, etc. No es muy informativo.
Ahora, mira el mismo código con una declaración de registro ligeramente modificada:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Como puedes ver, esta vez hemos incluido el propio objeto de excepción en nuestro mensaje de registro:
LOGGER.error("Error while executing main thread", ioe);
Eso resultaría en el siguiente registro de error en la consola con nuestra configuración por defecto:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Contiene información relevante – i.Es decir, el nombre de la clase, el método en el que se produjo el problema y, por último, el número de línea en el que se produjo el problema. Por supuesto, en situaciones de la vida real, los stack traces serán más largos, pero debe incluirlos para darle suficiente información para la depuración adecuada.
Para aprender más acerca de cómo manejar los stack traces de Java con Logstash vea Manejo de Stack Traces Multilínea con Logstash o mire Logagent que puede hacer eso por usted fuera de la caja.
Logging Java Exceptions
Cuando se trata de excepciones y stack traces de Java no sólo se debe pensar en todo el stack trace, las líneas donde apareció el problema, etc. También debe pensar en cómo no tratar con las excepciones.
Evite ignorar silenciosamente las excepciones. No querrá ignorar algo importante. Por ejemplo, no haga esto:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
Tampoco registre una excepción y láncela después. Eso significa que acabas de empujar el problema hacia arriba en la pila de ejecución. Evite cosas como esta también:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Si está interesado en aprender más sobre las excepciones, lea nuestra guía sobre el manejo de excepciones en Java donde cubrimos todo, desde lo que son hasta cómo atraparlas y arreglarlas.
Use el nivel de registro apropiado
Cuando escriba el código de su aplicación piense dos veces en un mensaje de registro determinado. No toda la información es igual de importante y no toda situación inesperada es un error o un mensaje crítico. Además, el uso de los niveles de registro de forma coherente – la información de un tipo similar debe estar en un nivel de gravedad similar.
Tanto la fachada SLF4J y cada marco de registro de Java que va a utilizar proporcionan métodos que se pueden utilizar para proporcionar un nivel de registro adecuado. Por ejemplo:
LOGGER.error("I/O error occurred during request processing", ioe);
Log en JSON
Si planeamos registrar y mirar los datos manualmente en un archivo o en la salida estándar, entonces el registro previsto estará más que bien. Es más amigable para el usuario – estamos acostumbrados a ello. Pero eso sólo es viable para aplicaciones muy pequeñas e incluso entonces se sugiere usar algo que permita correlacionar los datos de las métricas con los registros. Hacer tales operaciones en una ventana de terminal no es divertido y a veces simplemente no es posible. Si quieres almacenar los logs en el sistema de gestión y centralización de logs debes hacerlo en JSON. Esto se debe a que el análisis sintáctico no es gratuito, ya que normalmente implica el uso de expresiones regulares. Por supuesto, puedes pagar ese precio en el cargador de registros, pero por qué hacer eso si puedes registrar fácilmente en JSON. Registrar en JSON también significa un fácil manejo de las trazas de pila, así que otra ventaja. Bueno, también puedes simplemente registrar en un destino compatible con Syslog, pero eso es otra historia.
En la mayoría de los casos, para habilitar el registro en JSON en tu marco de registro de Java es suficiente con incluir la configuración adecuada. Por ejemplo, supongamos que tenemos el siguiente mensaje de registro incluido en nuestro código:
LOGGER.info("This is a log message that will be logged in JSON!");
Para configurar Log4J 2 para escribir mensajes de registro en JSON incluiríamos la siguiente configuración:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
El resultado sería el siguiente:
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Mantenga la estructura del registro consistente
La estructura de sus eventos de registro debe ser consistente. Esto no sólo es cierto dentro de una sola aplicación o conjunto de microservicios, sino que debe aplicarse en toda su pila de aplicaciones. Con eventos de registro estructurados de forma similar, será más fácil examinarlos, compararlos, correlacionarlos o simplemente almacenarlos en un almacén de datos dedicado. Es más fácil examinar los datos procedentes de tus sistemas cuando sabes que tienen campos comunes como la gravedad y el nombre de host, por lo que puedes cortar fácilmente los datos basándote en esa información. Para inspirarse, eche un vistazo a Sematext Common Schema aunque no sea usuario de Sematext.
Por supuesto, mantener la estructura no siempre es posible, porque su pila completa consiste en servidores desarrollados externamente, bases de datos, motores de búsqueda, colas, etc., cada uno de los cuales tiene su propio conjunto de registros y formatos de registro. Sin embargo, para mantener su cordura y la de su equipo, minimice el número de estructuras de mensajes de registro diferentes que puede controlar.
Una forma de mantener una estructura común es utilizar el mismo patrón para sus registros, al menos los que están utilizando el mismo marco de registro. Por ejemplo, si tus aplicaciones y microservicios usan Log4J 2 podrías usar un patrón como este:
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
Al usar un único o un conjunto muy limitado de patrones puedes estar seguro de que el número de formatos de logs se mantendrá pequeño y manejable.
Agrega contexto a tus logs
El contexto de la información es importante y para nosotros los desarrolladores y DevOps un mensaje de log es información. Mira la siguiente entrada de registro:
An error occurred!
Sabemos que ha aparecido un error en alguna parte de la aplicación. No sabemos dónde ocurrió, no sabemos qué tipo de error fue, sólo sabemos cuándo ocurrió. Ahora veamos un mensaje con algo más de información contextual:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
El mismo registro, pero con mucha más información contextual. Sabemos el hilo en el que ocurrió, sabemos en qué clase se generó el error. También modificamos el mensaje para incluir el usuario al que le ha ocurrido el error, así podemos volver a contactar con el usuario si es necesario. También podríamos incluir información adicional como contextos de diagnóstico. Piensa en lo que necesitas e inclúyelo.
Para incluir información de contexto no hay que hacer mucho cuando se trata del código que se encarga de generar el mensaje de registro. Por ejemplo, el PatternLayout de Log4J 2 te da todo lo que necesitas para incluir la información de contexto. Puedes ir con un patrón muy simple como este:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
Eso resultará en un mensaje de registro similar al siguiente:
17:13:08.059 INFO - This is the first INFO level log message!
Pero también puedes incluir un patrón que incluirá mucha más información:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
Eso dará como resultado un mensaje de registro como el siguiente:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java Logging in Containers
Piensa en el entorno en el que se va a ejecutar tu aplicación. Hay una diferencia en la configuración del logging cuando estás ejecutando tu código Java en una VM o en una máquina bare-metal, es diferente cuando lo ejecutas en un entorno de contenedores, y por supuesto, es diferente cuando ejecutas tu código Java o Kotlin en un dispositivo Android.
Para configurar el logging en un entorno de contenedores necesitas elegir el enfoque que quieres tomar. Puede utilizar uno de los controladores de registro proporcionados – como el journald, logagent, Syslog, o archivo JSON. Para ello, recuerda que tu aplicación no debe escribir el archivo de registro en el almacenamiento efímero del contenedor, sino en la salida estándar. Eso se puede hacer fácilmente configurando su marco de registro para escribir el registro en la consola. Por ejemplo, con Log4J 2 sólo tendrías que usar la siguiente configuración de appender:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
También puedes omitir por completo los controladores de logging y enviar los logs directamente a tu solución de logs centralizada como nuestro Sematext Cloud:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
No registres ni mucho ni poco
Como desarrolladores tendemos a pensar que todo puede ser importante – tendemos a marcar cada paso de nuestro algoritmo o código de negocio como importante. Por otro lado, a veces hacemos lo contrario – no añadimos registro donde deberíamos o registramos sólo los niveles de registro FATAL y ERROR. Ambos enfoques no son muy buenos. Cuando escribas tu código y añadas el registro, piensa en lo que será importante para ver si la aplicación funciona correctamente y lo que será importante para poder diagnosticar un estado erróneo de la aplicación y arreglarlo. Usa esto como luz de guía para decidir qué y dónde registrar. Tenga en cuenta que añadir demasiados registros terminará en la fatiga de la información y no tener suficiente información dará lugar a la incapacidad de solucionar problemas.
Mantenga la audiencia en mente
En la mayoría de los casos, usted no será la única persona que mira los registros. Recuerde siempre que. Hay múltiples actores que pueden estar mirando los registros.
El desarrollador puede estar mirando los registros para la solución de problemas o durante las sesiones de depuración. Para estas personas, los registros pueden ser detallados, técnicos e incluir información muy profunda relacionada con el funcionamiento del sistema. Tal persona también tendrá acceso al código o incluso conocerá el código y puede asumirlo.
Luego están los DevOps. Para ellos, los eventos de registro serán necesarios para la resolución de problemas y deben incluir información útil para el diagnóstico. Puede asumir el conocimiento del sistema, su arquitectura, sus componentes y la configuración de los mismos, pero no debe asumir el conocimiento sobre el código de la plataforma.
Por último, los registros de su aplicación pueden ser leídos por sus propios usuarios. En tal caso, los registros deben ser lo suficientemente descriptivos como para ayudar a solucionar el problema, si es que eso es posible, o dar suficiente información al equipo de soporte que ayuda al usuario. Por ejemplo, el uso de Sematext para la monitorización implica la instalación y ejecución de un agente de monitorización. Si está detrás de un cortafuegos muy restrictivo y el agente no puede enviar las métricas a Sematext, registra los errores con el objetivo de que los propios usuarios de Sematext puedan verlos también.
Podríamos ir más allá e identificar aún más actores que podrían estar buscando en los registros, pero esta breve lista debería darle una idea de lo que debería pensar al escribir sus mensajes de registro.
Evite registrar información sensible
La información sensible no debería estar presente en los registros o debería estar enmascarada. Contraseñas, números de tarjetas de crédito, números de la seguridad social, tokens de acceso, etc., todo ello puede ser peligroso si se filtra o acceden a él quienes no deberían verlo. Hay dos cosas que debe considerar.
Piense si la información sensible es realmente esencial para la resolución de problemas. ¿Quizás en lugar del número de la tarjeta de crédito es suficiente con guardar la información sobre el identificador de la transacción y la fecha de la misma? Tal vez no sea necesario guardar el número de la seguridad social en los registros cuando se puede guardar fácilmente el identificador del usuario. Piense en estas situaciones, piense en los datos que almacena, y sólo escriba datos sensibles cuando sea realmente necesario.
Lo segundo es enviar los registros con información sensible a un servicio de registros alojados. Hay muy pocas excepciones en las que no se debe seguir el siguiente consejo. Si sus logs tienen y necesitan tener información sensible almacenada, enmascare o elimínela antes de enviarlos a su almacén de logs centralizado. La mayoría de los cargadores de registros populares, como nuestro propio Logagent, incluyen una funcionalidad que permite eliminar o enmascarar los datos sensibles.
Por último, el enmascaramiento de la información sensible se puede hacer en el propio marco de registro. Veamos cómo se puede hacer extendiendo Log4j 2. Nuestro código que produce eventos de registro tiene el siguiente aspecto (el ejemplo completo se puede encontrar en Sematext Github):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Si se ejecutara el ejemplo completo desde Github la salida sería la siguiente:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Se puede ver que el número de la tarjeta de crédito fue enmascarado. Esto se hizo porque añadimos un Convertidor personalizado que comprueba si el Marcador dado se pasa a lo largo del evento de registro y trata de reemplazar un patrón definido. La implementación de dicho Convertidor tiene el siguiente aspecto:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
Es muy simple y podría escribirse de forma más optimizada y también debería manejar todos los posibles formatos de números de tarjetas de crédito, pero es suficiente para este propósito.
Antes de pasar a la explicación del código también me gustaría mostraros el archivo de configuración log4j2.xml de este ejemplo:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Como podéis ver, hemos añadido el atributo packages en nuestra Configuración para indicarle al framework dónde buscar nuestro conversor. Luego hemos utilizado el patrón %sc para proporcionar el mensaje de registro. Lo hacemos porque no podemos sobrescribir el patrón %m por defecto. Una vez que Log4j2 encuentra nuestro patrón %sc utilizará nuestro convertidor que toma el mensaje formateado del evento de registro y utiliza una simple regex y reemplaza los datos si se encontró. Tan simple como eso.
Una cosa a notar aquí es que estamos usando la funcionalidad de Marker. La coincidencia de Regex es costosa y no queremos hacer eso para cada mensaje de registro. Por eso marcamos los eventos de registro que deben ser procesados con el Marker creado, de modo que sólo se comprueban los marcados.
Usa una solución de gestión de registros para centralizar &Monitorizar los registros de Java
Con la complejidad de las aplicaciones, el volumen de tus registros también crecerá. Usted puede salirse con la suya con el registro en un archivo y sólo el uso de registros cuando se necesita la solución de problemas, pero cuando la cantidad de datos crece rápidamente se convierte en difícil y lento para solucionar problemas de esta manera Cuando esto sucede, considere el uso de una solución de gestión de registros para centralizar y supervisar sus registros. Puede optar por una solución interna basada en el software de código abierto, como Elastic Stack, o utilizar una de las herramientas de gestión de registros disponibles en el mercado, como Sematext Logs.
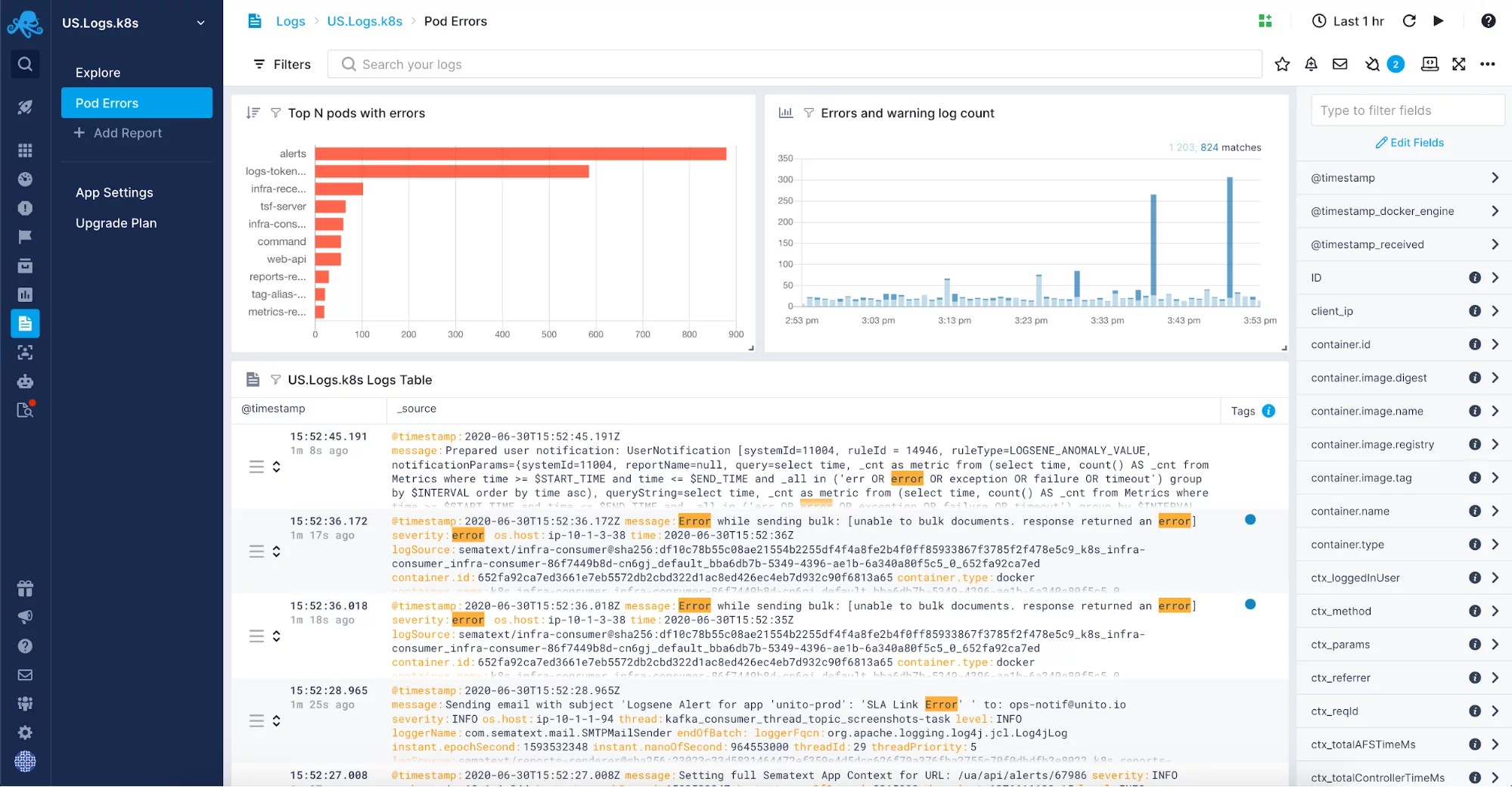
Una solución de centralización de registros totalmente gestionada le dará la libertad de no tener que gestionar otra parte más, normalmente bastante compleja, de su infraestructura. En su lugar, podrá centrarse en su aplicación y sólo tendrá que configurar el envío de registros. Es posible que quiera incluir registros como los de recolección de basura de la JVM en su solución de registros gestionados. Después de activarlos para sus aplicaciones y sistemas que trabajan en la JVM, querrá agregar los registros en un solo lugar para la correlación de registros, el análisis de registros y para ayudarle a ajustar la recolección de basura en las instancias de la JVM. Estos registros correlacionados con las métricas son una fuente de información inestimable para solucionar problemas relacionados con la recolección de basura.
Si está interesado en ver cómo Sematext Logs se compara con soluciones similares, diríjase a nuestro artículo sobre el mejor software de gestión de registros o a la entrada del blog en la que revisamos algunas de las principales herramientas de análisis de registros, pero le recomendamos que utilice la prueba gratuita de 14 días para explorar completamente sus características. Pruébalo y compruébalo tú mismo
Conclusión
Incorporar todas y cada una de las buenas prácticas puede no ser fácil de implementar de inmediato, especialmente para las aplicaciones que ya están en vivo y trabajando en producción. Pero si te tomas el tiempo y despliegas las sugerencias una tras otra, empezarás a ver un aumento en la utilidad de tus registros. Para más consejos sobre cómo sacar el máximo partido a tus logs, te recomendamos que también te pases por nuestro otro artículo sobre buenas prácticas de logging donde explicamos los entresijos que deberías seguir independientemente del tipo de app con la que trabajes. Y recuerda que en Sematext ayudamos a las organizaciones con sus configuraciones de logs ofreciendo consultoría de logs, así que acércate si tienes problemas y estaremos encantados de ayudarte.
Compartir
.
Deja una respuesta