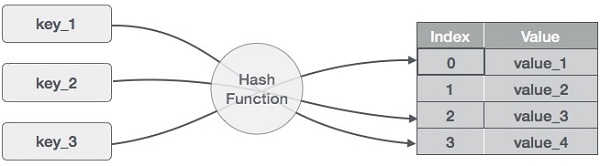
La Tabla Hash es una estructura de datos que almacena datos de forma asociativa. En una tabla hash, los datos se almacenan en un formato de matriz, donde cada valor de datos tiene su propio valor de índice único. El acceso a los datos es muy rápido si conocemos el índice de los datos deseados.
Así, se convierte en una estructura de datos en la que las operaciones de inserción y búsqueda son muy rápidas independientemente del tamaño de los datos. La tabla Hash utiliza un array como medio de almacenamiento y utiliza la técnica del hash para generar un índice en el que se va a insertar un elemento o desde el que se va a localizar.
Hashing
Hashing es una técnica para convertir un rango de valores clave en un rango de índices de un array. Vamos a utilizar el operador módulo para obtener un rango de valores clave. Considere un ejemplo de tabla hash de tamaño 20, y los siguientes elementos se van a almacenar. Los elementos están en el formato (clave,valor).
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Clave | Hash | Índice de la matriz |
|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 |
| 2 | 2 % 20 = 2 | 2 | |
| 3 | 42 | 42 % 20 = 2 | 2 |
| 4 | 4 | 4 % 20 = 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 |
Sondeo lineal
Como podemos ver, puede ocurrir que la técnica del hashing se utilice para crear un índice ya utilizado del array. En tal caso, podemos buscar la siguiente ubicación vacía en el array buscando en la siguiente celda hasta encontrar una celda vacía. Esta técnica se llama sondeo lineal.
| Sr.No. | Clave | Hash | Índice de la matriz | Después del sondeo lineal, Array Index |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
Operaciones básicas
Las siguientes son las operaciones primarias básicas de una tabla hash.
-
Buscar – Busca un elemento en una tabla hash.
-
Insertar – Inserta un elemento en una tabla hash.
-
Eliminar – Elimina un elemento de una tabla hash.
DataItem
Define un elemento de datos que tiene unos datos y una clave, en base a los cuales se va a realizar la búsqueda en una tabla hash.
struct DataItem { int data; int key;};
Método Hash
Define un método hash para calcular el código hash de la clave del elemento de datos.
int hashCode(int key){ return key % SIZE;}
Operación de búsqueda
Cuando se va a buscar un elemento, calcula el código hash de la clave pasada y localiza el elemento usando ese código hash como índice en el array. Utilizar el sondeo lineal para obtener el elemento adelante si el elemento no se encuentra en el código hash calculado.
Ejemplo
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray != NULL) { if(hashArray->key == key) return hashArray; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Operación de inserción
Siempre que se vaya a insertar un elemento, calcular el código hash de la clave pasada y localizar el índice utilizando ese código hash como índice en el array. Utiliza el sondeo lineal para obtener la ubicación vacía, si se encuentra un elemento en el código hash calculado.
Ejemplo
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray != NULL && hashArray->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray = item; }
Operación de borrado
Cuando se vaya a borrar un elemento, calcula el código hash de la clave pasada y localiza el índice utilizando ese código hash como índice en el array. Utilizar el sondeo lineal para obtener el elemento adelante si no se encuentra un elemento en el código hash calculado. Cuando se encuentra, almacenar un elemento ficticio allí para mantener el rendimiento de la tabla hash intacta.
Ejemplo
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray !=NULL) { if(hashArray->key == key) { struct DataItem* temp = hashArray; //assign a dummy item at deleted position hashArray = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Para saber sobre la implementación de hash en el lenguaje de programación C, por favor haga clic aquí.
Deja una respuesta