Inscríbete en nuestros resúmenes diarios del siempre cambiante panorama del marketing de búsqueda.
Nota: Al enviar este formulario, aceptas los términos de Third Door Media. Respetamos su privacidad.

En los foros de Internet y en los grupos de Facebook relacionados con el contenido, a menudo se desatan discusiones sobre el funcionamiento de Googlebot -al que aquí llamaremos tiernamente GB- y sobre lo que puede y no puede ver, qué tipo de enlaces visita y cómo influye en el SEO.
En este artículo, presentaré los resultados de mi experimento de tres meses de duración.
Casi a diario durante los últimos tres meses, GB me ha visitado como un amigo que pasa a tomar una cerveza.
A veces estaba solo:
: 66.249.76.136 /page1.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
A veces trae a sus compañeros:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, como Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Y nos divertimos mucho jugando a diferentes juegos:
Catch: Observé cómo a GB le encanta ejecutar redireccionamientos 301 y rastrear imágenes, y correr de las canónicas.
Esconderse: Googlebot se escondía en el contenido oculto (que, como afirman sus padres, no tolera y evita)
Supervivencia: Preparé trampas y esperé a que las soltara.
Obstáculos: Coloqué obstáculos con varios niveles de dificultad para ver cómo mi amiguito se enfrentaba a ellos.
Como probablemente puedes deducir, no me decepcionó. Nos divertimos mucho y nos hicimos buenos amigos. Creo que nuestra amistad tiene un futuro brillante.
Pero vayamos al grano!
Construí un sitio web con contenido relacionado con los méritos sobre una agencia de viajes interestelares que ofrecía vuelos a planetas aún no descubiertos en nuestra galaxia y más allá.
El contenido parecía tener muchos méritos cuando en realidad era un montón de tonterías.
La estructura del sitio web experimental tenía este aspecto:
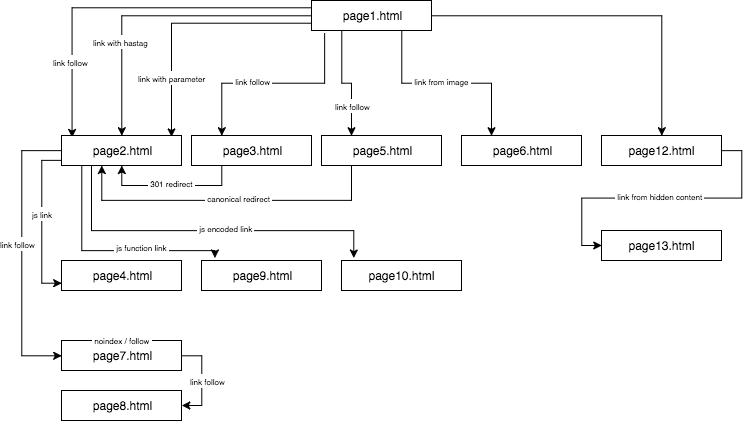
Proporcioné un contenido único y me aseguré de que cada ancla/título/alt, así como otros coeficientes, fueran globalmente únicos (palabras falsas). Para facilitar las cosas al lector, en la descripción no utilizaré nombres como ancla cutroicano matestito, sino que me referiré a ellos como ancla1, etc.
Le sugiero que mantenga el mapa anterior abierto en una ventana aparte mientras lee este artículo.
- Parte 1: El primer enlace cuenta
- Enlace a un sitio web con un ancla
- Enlace a un sitio web con un parámetro
- Enlace a un sitio web desde una redirección
- Enlace a una página utilizando la etiqueta canónica
- Parte 2: Presupuesto de rastreo
- Enlace JavaScript con un evento onclick
- Enlace javascript con función interna
- Enlace javascript con codificación
- Parte 3: Contenido oculto
- Acerca del autor
Parte 1: El primer enlace cuenta
Una de las cosas que quería probar en este experimento de SEO era la regla del primer enlace cuenta – si se puede omitir y cómo influye en la optimización.
La regla del primer enlace cuenta dice que en una página, Google Bot ve sólo el primer enlace a una subpágina. Si tienes dos enlaces a la misma subpágina en una página, el segundo será ignorado, según esta regla. El Bot de Google ignorará el ancla en el segundo y en cada enlace consecutivo mientras calcula el rango de la página.
Es un problema ampliamente supervisado por muchos especialistas, pero que está presente especialmente en las tiendas online, donde los menús de navegación distorsionan significativamente la estructura del sitio web.
En la mayoría de las tiendas, tenemos un menú desplegable estático (visible en el origen de la página), que da, por ejemplo, cuatro enlaces a categorías principales y 25 enlaces ocultos a subcategorías. Durante el mapeo de la estructura de una página, GB ve todos los enlaces (en cada página con un menú), lo que resulta en que todas las páginas tienen la misma importancia durante el mapeo y su poder (jugo) se distribuye de manera uniforme, lo que se ve más o menos así:
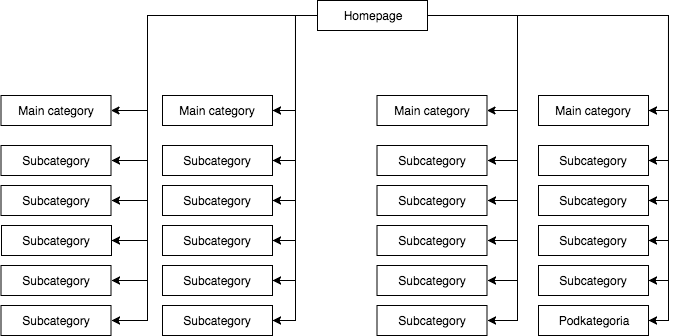
La estructura de la página más común pero, en mi opinión, incorrecta.
El ejemplo anterior no puede llamarse una estructura adecuada porque todas las categorías están vinculadas desde todos los sitios donde hay un menú. Por lo tanto, tanto la página de inicio como todas las categorías y subcategorías tienen un número igual de enlaces entrantes, y el poder de todo el servicio web fluye a través de ellos con igual fuerza. Por lo tanto, el poder de la página de inicio (que suele ser la fuente de la mayor parte del poder debido al número de enlaces entrantes) se está dividiendo en 24 categorías y subcategorías, por lo que cada una de ellas recibe sólo el 4 por ciento del poder de la página de inicio.
Cómo debería ser la estructura:

Si necesita probar rápidamente la estructura de su página y rastrearla como hace Google, Screaming Frog es una herramienta útil.
En este ejemplo, la potencia de la página de inicio se divide en cuatro y cada una de las categorías recibe el 25 por ciento de la potencia de la página de inicio y distribuye parte de ella a las subcategorías. Esta solución también proporciona una mayor posibilidad de enlace interno. Por ejemplo, cuando se escribe un artículo en el blog de la tienda y se quiere enlazar a una de las subcategorías, GB notará el enlace mientras rastrea el sitio web. En el primer caso, no lo hará debido a la regla del primer enlace cuenta. Si el enlace a una subcategoría estaba en el menú del sitio web, entonces el del artículo será ignorado.
Empecé este experimento de SEO con las siguientes acciones:
- Primero, en la página1.html, incluí un enlace a una subpágina page2.html como un enlace dofollow clásico con un ancla: anchor1.
- A continuación, en el texto de la misma página, incluí referencias ligeramente modificadas para verificar si GB estaría ansioso por rastrearlas.
Para ello, probé las siguientes soluciones:
- A la página de inicio del servicio web, le asigné un enlace externo dofollow para una frase con ancla URL (por lo que cualquier enlace externo de la página de inicio y las subpáginas para las frases dadas estaba fuera de cuestión) – aceleró la indexación del servicio.
- Esperé a que la página2.html empezara a posicionarse para una frase desde el primer enlace dofollow (anchor1) procedente de la página1.html. Esta frase falsa, o cualquier otra que probé no pudo ser encontrada en la página de destino. Supuse que si otros enlaces funcionaban, entonces la página2.html también se clasificaría en los resultados de búsqueda para otras frases procedentes de otros enlaces. Tardé unos 45 días. Y entonces pude hacer la primera conclusión importante.
Incluso un sitio web, donde una palabra clave no está ni en el contenido, ni en el meta título, pero está vinculado con un ancla investigado, puede fácilmente clasificar en los resultados de búsqueda más alto que un sitio web que contiene esta palabra, pero no está vinculado a una palabra clave.
Además, la página de inicio (page1.html), que contenía la frase investigada, era la página más fuerte del servicio web (enlazada desde el 78 por ciento de las subpáginas) y, aun así, se clasificó más bajo en la frase investigada que la subpágina (page2.html) vinculada a la frase investigada.
A continuación, presento cuatro tipos de enlaces que he probado, todos los cuales vienen después del primer enlace dofollow que lleva a page2.html.
Enlace a un sitio web con un ancla
< a href=»page2.html#testhash» >anchor2< /a >
El primero de los enlaces adicionales que viene en el código detrás del enlace dofollow era un enlace con un ancla (un hashtag). Quería ver si GB pasaría por el enlace y también indexaría la página2.html bajo la frase anchor2, a pesar de que el enlace lleva a esa página (page2.html) pero la URL que se cambia a page2.html#testhash usa anchor2.
Desgraciadamente, GB nunca quiso recordar esa conexión y no dirigió el poder a la subpágina page2.html para esa frase. Como resultado, en los resultados de la búsqueda de la frase anchor2 en el día de escribir este artículo, sólo aparece la subpágina page1.html, donde se encuentra la palabra en el ancla del enlace. Al buscar en Google la frase testhash, nuestro dominio tampoco aparece.
Enlace a un sitio web con un parámetro
page2.html?parameter=1
Inicialmente, GB se interesó por esta curiosa parte de la URL justo después de la marca de consulta y el ancla dentro del enlace anchor3.
Intrigado, GB intentaba averiguar qué quería decir. Pensó: «¿Es una adivinanza?». Para evitar indexar el contenido duplicado bajo las otras URLs, la página canónica2.html se apuntaba a sí misma. Los logs registraron en total 8 rastreos en esta dirección, pero las conclusiones fueron bastante tristes:
- Después de 2 semanas, la frecuencia de las visitas de GB disminuyó significativamente hasta que finalmente se fue y no volvió a rastrear ese enlace.
- page2.html no se indexó bajo la frase anchor3, ni tampoco el parámetro con la URL parameter1. Según Search Console, este enlace no existe (no se cuenta entre los enlaces entrantes), pero al mismo tiempo, la frase anchor3 aparece como frase anclada.
Enlace a un sitio web desde una redirección
Quería forzar a GB a rastrear más mi sitio web, lo que dio lugar a que GB, cada par de días, introdujera el enlace dofollow con un ancla4 en la página1.html que lleva a la página3.html, que redirige con un código 301 a la página2.html. Desgraciadamente, al igual que en el caso de la página con parámetro, al cabo de 45 días la página2.html aún no se posicionaba en los resultados de búsqueda para la frase anchor4 que aparecía en el enlace redirigido en la página1.html.
Sin embargo, en Google Search Console, en la sección Anchor Texts, el anchor4 está visible e indexado. Esto podría indicar que, después de un tiempo, la redirección empezará a funcionar como se espera, de modo que la página2.html se clasificará en los resultados de búsqueda por el ancla4 a pesar de ser el segundo enlace a la misma página de destino dentro del mismo sitio web.
Enlace a una página utilizando la etiqueta canónica
En la página1.html, he colocado una referencia a la página5.html (enlace de seguimiento) con un ancla anchor5. Al mismo tiempo, en la página5.html había un contenido único, y en su cabecera, había una etiqueta canónica a la página2.html.
< link rel=»canonical» href=»https://example.com/page2.html» />
Esta prueba dio los siguientes resultados:
- El enlace de la frase anchor5 que dirigía a page5.html redirigiendo canónicamente a page2.html no se transfirió a la página de destino (al igual que en los otros casos).
- page5.html se indexó a pesar de la etiqueta canónica.
- page5.html no se clasificó en los resultados de búsqueda para anchor5.
- page5.html se clasificó por las frases utilizadas en el texto de la página, lo que indicaba que GB ignoraba totalmente las etiquetas canónicas.
Me atrevería a afirmar que el uso de rel=canonical para evitar la indexación de algunos contenidos (por ejemplo, durante el filtrado) simplemente no podría funcionar.
Parte 2: Presupuesto de rastreo
Mientras diseñaba una estrategia de SEO, quería hacer que GB bailara a mi son y no al revés. Para ello, verifiqué los procesos de SEO a nivel de los logs del servidor (logs de acceso y logs de error) lo que me proporcionó una gran ventaja. Gracias a ello, conocí cada movimiento de GB y cómo reaccionaba a los cambios que introduje (reestructuración de la web, puesta al revés del sistema de enlaces internos, forma de mostrar la información) dentro de la campaña SEO.
Una de mis tareas durante la campaña SEO fue reconstruir una web de forma que GB visitara sólo aquellas URLs que pudiera indexar y que nosotros quisiéramos que indexara. En pocas palabras: en el índice de Google sólo deberían estar las páginas que son importantes para nosotros desde el punto de vista del SEO. Por otro lado, GB sólo debería rastrear las páginas web que queremos que sean indexadas por Google, lo cual no es obvio para todo el mundo, por ejemplo, cuando una tienda online implementa el filtrado por colores, tallas y precios, y lo hace manipulando los parámetros de la URL, por ejemplo:
ejemplo.com/mujeres/zapatos/?color=rojo&talla=40&precio=200-250
Puede resultar que una solución que permita a GB rastrear las URLs dinámicas le haga dedicar tiempo a recorrerlas (y posiblemente indexarlas) en lugar de rastrear la página.
ejemplo.com/mujeres/zapatos/
Estas URLs creadas dinámicamente no sólo son inútiles, sino que son potencialmente dañinas para el SEO porque pueden ser confundidas con contenido fino, lo que provocará la caída de los rankings del sitio web.
Dentro de este experimento también quise comprobar algunos métodos de estructuración sin utilizar rel=»nofollow», bloqueando GB en el archivo robots.txt o colocando parte del código HTML en marcos que son invisibles para el bot (iframe bloqueado).
Probé tres tipos de enlaces JavaScript.
Enlace JavaScript con un evento onclick
Un enlace simple construido en JavaScript
< a href=»javascript:void(0)» onclick=»window.location.href =’page4.html'» >anchor6< /a >
GB pasó fácilmente a la subpágina page4.html e indexó toda la página. La subpágina no aparece en los resultados de búsqueda para la frase anchor6, y esta frase no se encuentra en la sección Anchor Texts de Google Search Console. La conclusión es que el enlace no transfirió el jugo.
Para resumir:
- Un enlace JavaScript clásico permite a Google rastrear el sitio web e indexar las páginas con las que se encuentra.
- No transfiere jugo – es neutral.
Enlace javascript con función interna
Decidí plantear el juego pero, para mi sorpresa, GB superó el obstáculo en menos de 2 horas tras la publicación del enlace.
<a href=»javascript:void(0)» class=»js-link» data-url=»page9.html» >anchor7< /a >
Para hacer funcionar este enlace, utilicé una función externa, cuyo objetivo era la lectura de la URL de los datos y la redirección -sólo la redirección de un usuario, como esperaba- a la página9.html de destino. Como en el caso anterior, la página9.html había sido totalmente indexada.
Lo interesante es que, a pesar de la falta de otros enlaces entrantes, la página9.html era la tercera página más visitada por GB en todo el servicio web, justo después de la página1.html y la página2.html.
Ya había utilizado este método antes para estructurar servicios web. Sin embargo, como podemos ver, ya no funciona. En SEO nada vive para siempre, aparte de las Páginas Amarillas.
Enlace javascript con codificación
Aún así, no me iba a rendir y decidí que debía haber una forma de cerrarle la puerta en la cara a GB de forma efectiva. Así que construí una función sencilla, codificando los datos con un algoritmo base64, y la referencia quedó así:
< a href=»javascript:void(0)» class=»js-link» data-url=»cGFnZTEwLmh0bWw=» >anchor8< /a >
Como resultado, GB fue incapaz de producir un código JavaScript que decodificara el contenido de un atributo data-URL y que redirigiera. Y ahí estaba. ¡Tenemos una forma de estructurar un servicio web sin usar rel=nonfollows para evitar que los bots rastreen donde quieran! De esta manera, no desperdiciamos nuestro presupuesto de rastreo, lo que es especialmente importante en el caso de los grandes servicios web, y GB finalmente baila a nuestro son. Ya sea que la función se haya introducido en la misma página en la sección head o en un archivo JS externo, no hay evidencia de un bot ni en los registros del servidor ni en Search Console.
Parte 3: Contenido oculto
En la prueba final, quería comprobar si el contenido de, por ejemplo, las pestañas ocultas sería considerado e indexado por GB o si Google renderizaba una página de este tipo e ignoraba el texto oculto, como han estado afirmando algunos especialistas.
Quería confirmar o descartar esta afirmación. Para ello, coloqué un muro de texto con más de 2000 signos en la página12.html y oculté un bloque de texto con aproximadamente el 20 por ciento del texto (400 signos) en hojas de estilo en cascada y añadí el botón de mostrar más. Dentro del texto oculto había un enlace a la página13.html con un ancla anchor9.
No hay duda de que un bot puede renderizar una página. Podemos observarlo tanto en Google Search Console como en Google Insight Speed. Sin embargo, mis pruebas revelaron que un bloque de texto que se mostraba tras hacer clic en el botón de mostrar más se indexaba completamente. Las frases ocultas en el texto aparecían en los resultados de búsqueda y GB seguía los enlaces ocultos en el texto. Además, los anclajes de los enlaces de un bloque de texto oculto eran visibles en Google Search Console en la sección Anchor Text y page13.html también empezó a posicionarse en los resultados de búsqueda para la palabra clave anchor9.
Esto es crucial para las tiendas online, donde el contenido suele colocarse en pestañas ocultas. Ahora estamos seguros de que GB ve el contenido en las pestañas ocultas, las indexa y transfiere el jugo de los enlaces que están ocultos allí.
La conclusión más importante que estoy sacando de este experimento es que no he encontrado una forma directa de eludir la regla del primer enlace cuenta mediante el uso de enlaces modificados (enlaces con parámetro, redireccionamientos 301, canónicos, enlaces ancla). Al mismo tiempo, es posible construir la estructura de un sitio web utilizando enlaces Javascript, gracias a lo cual nos libramos de las restricciones de la Regla del Primer Recuento de Enlaces. Además, Google Bot puede ver e indexar el contenido oculto en los marcadores y sigue los enlaces ocultos en ellos.
Inscríbete en nuestros resúmenes diarios del siempre cambiante panorama del marketing de búsqueda.
Nota: Al enviar este formulario, aceptas los términos de Third Door Media. Respetamos su privacidad.
Acerca del autor

«No acepte «sólo» alta calidad. Cualquiera puede hacerlo. Si el cielo es el límite, busca un cielo más alto». Max Cyrek es CEO de Cyrek Digital, consultor de marketing digital y evangelista del SEO. A lo largo de su carrera, Max, junto con su equipo de más de 30 personas, ha trabajado con cientos de empresas ayudándolas a triunfar. Lleva casi diez años trabajando en marketing digital y se ha especializado en SEO técnico, gestionando proyectos de marketing de éxito.
Deja una respuesta