La gente está creando, compartiendo y almacenando datos a un ritmo más rápido que en cualquier otro momento de la historia. Cuando se trata de innovar en el almacenamiento y la transmisión de esos datos, en Facebook estamos haciendo avances no sólo en el hardware, como discos duros más grandes y equipos de red más rápidos, sino también en el software. El software ayuda a procesar los datos mediante la compresión, que codifica la información, como el texto, las imágenes y otras formas de datos digitales, utilizando menos bits que el original. Estos archivos más pequeños ocupan menos espacio en los discos duros y se transmiten más rápidamente a otros sistemas. Sin embargo, la compresión y descompresión de la información tiene una contrapartida: el tiempo. Cuanto más tiempo se dedique a comprimir un archivo más pequeño, más lento será el procesamiento de los datos.
Hoy en día, el estándar de compresión de datos reinante es Deflate, el algoritmo central dentro de Zip, gzip y zlib . Durante dos décadas, ha proporcionado un impresionante equilibrio entre velocidad y espacio y, como resultado, se utiliza en casi todos los dispositivos electrónicos modernos (y, no por casualidad, se utiliza para transmitir cada byte de la propia entrada del blog que está leyendo). A lo largo de los años, otros algoritmos han ofrecido una mejor compresión o una compresión más rápida, pero rara vez ambas. Creemos que hemos cambiado esto.
Estamos encantados de anunciar Zstandard 1.0, un nuevo algoritmo de compresión y una implementación diseñada para escalar con el hardware moderno y comprimir más pequeño y más rápido. Zstandard combina los recientes avances en compresión, como la Entropía de Estado Finito, con un diseño que da prioridad al rendimiento, y luego optimiza la implementación para las propiedades únicas de las CPUs modernas. Como resultado, mejora las compensaciones hechas por otros algoritmos de compresión y tiene un amplio rango de aplicabilidad con una velocidad de descompresión muy alta. Zstandard, disponible ahora bajo la licencia BSD, está diseñado para ser utilizado en casi todos los escenarios de compresión sin pérdidas, incluyendo muchos donde los algoritmos actuales no son aplicables.
- Comparación de la compresión
- Escalabilidad
- Dentro del capó
- Memoria
- Un formato diseñado para la ejecución en paralelo
- Diseño sin ramificaciones
- Entropía de Estado Finito: Un compresor probabilístico de nueva generación
- Modelado de código de repetición
- Zstandard en la práctica
- Datos pequeños
- Diccionarios en acción
- Elegir un nivel de compresión
- Probarlo
- Más por venir
Comparación de la compresión
Hay tres métricas estándar para comparar algoritmos e implementaciones de compresión:
- Tasa de compresión: El tamaño original (numerador) comparado con el tamaño comprimido (denominador), medido en datos sin unidades como una relación de tamaño de 1,0 o superior.
- Velocidad de compresión: La rapidez con la que podemos hacer los datos más pequeños, medida en MB/s de datos de entrada consumidos.
- Velocidad de descompresión: la rapidez con la que podemos reconstruir los datos originales a partir de los datos comprimidos, medida en MB/s para la velocidad a la que se producen los datos a partir de los datos comprimidos.
El tipo de datos que se comprimen puede afectar a estas métricas, por lo que muchos algoritmos están ajustados para tipos de datos específicos, como texto en inglés, secuencias genéticas o imágenes rasterizadas. Sin embargo, Zstandard, al igual que zlib, está pensado para la compresión de propósito general para una variedad de tipos de datos. Para representar los algoritmos con los que se espera que funcione Zstandard, en este post utilizaremos el corpus Silesia, un conjunto de archivos que representan los tipos de datos típicos que se utilizan a diario.
Algunos de los algoritmos e implementaciones más utilizados hoy en día son zlib, lz4 y xz. Cada uno de estos algoritmos ofrece diferentes compensaciones: lz4 busca la velocidad, xz busca mayores ratios de compresión y zlib busca un buen equilibrio entre velocidad y tamaño. La tabla siguiente indica las compensaciones aproximadas de la relación de compresión y la velocidad por defecto de los algoritmos para el corpus Silesia, comparando los algoritmos por lzbench, una prueba de referencia pura en memoria destinada a modelar el rendimiento bruto de los algoritmos.
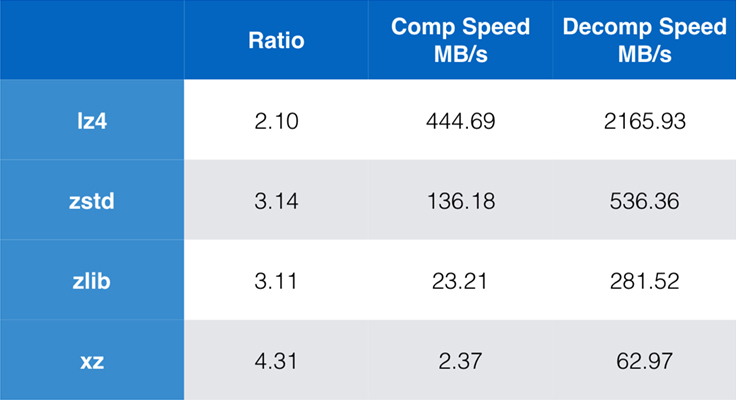
Como se ha señalado, a menudo hay compromisos drásticos entre la velocidad y el tamaño. El algoritmo más rápido, lz4, da lugar a ratios de compresión más bajos; xz, que tiene el mayor ratio de compresión, sufre de una velocidad de compresión lenta. Sin embargo, Zstandard, con la configuración por defecto, muestra mejoras sustanciales tanto en la velocidad de compresión como en la de descompresión, a la vez que comprime con el mismo ratio que zlib.
Si bien el rendimiento del algoritmo puro es importante cuando la compresión está incrustada dentro de una aplicación más grande, es extremadamente común utilizar también herramientas de línea de comandos para la compresión – por ejemplo, para comprimir archivos de registro, tarballs, u otros datos similares destinados al almacenamiento o la transferencia. En estos casos, el rendimiento suele verse afectado por la sobrecarga, como la suma de comprobación. Este gráfico muestra la comparación de las herramientas de línea de comandos gzip y zstd en Centos 7 construido con el compilador por defecto del sistema.
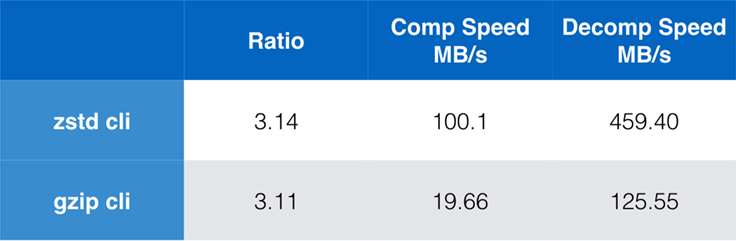
Las pruebas se realizaron cada una 10 veces, con los tiempos mínimos tomados, y se realizaron en ramdisk para evitar la sobrecarga del sistema de archivos. Estos fueron los comandos (que utilizan los niveles de compresión por defecto para ambas herramientas):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullEscalabilidad
Si un algoritmo es escalable, tiene la capacidad de adaptarse a una amplia variedad de requisitos, y Zstandard está diseñado para sobresalir en el panorama actual y escalar en el futuro. La mayoría de los algoritmos tienen «niveles» basados en compensaciones de tiempo/espacio: Cuanto más alto es el nivel, mayor es la compresión que se consigue con una pérdida de velocidad de compresión. Zlib ofrece nueve niveles de compresión; Zstandard ofrece actualmente 22, lo que permite una compensación flexible y granular entre la velocidad de compresión y los ratios para los datos futuros. Por ejemplo, podemos utilizar el nivel 1 si la velocidad es lo más importante y el nivel 22 si el tamaño es lo más importante.
A continuación se muestra un gráfico de la velocidad de compresión y la relación lograda para todos los niveles de Zstandard y zlib. El eje x es una escala logarítmica decreciente en megabytes por segundo; el eje y es el ratio de compresión alcanzado. Para comparar los algoritmos, puedes elegir una velocidad para ver los distintos ratios que alcanzan los algoritmos a esa velocidad. Del mismo modo, puede elegir una relación y ver la velocidad de los algoritmos cuando alcanzan ese nivel.
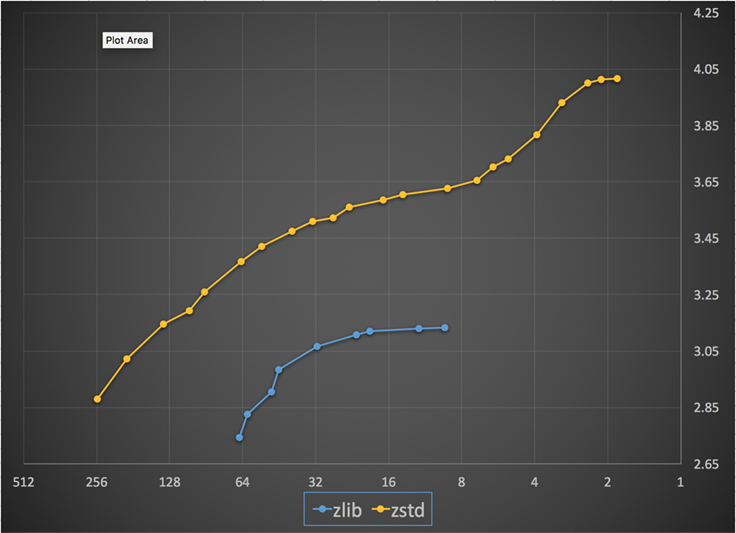
Para cualquier línea vertical (es decir, la velocidad de compresión), Zstandard consigue una relación de compresión mayor. Para el corpus de Silesia, la velocidad de descompresión -independientemente del ratio- fue de aproximadamente 550 MB/s para Zstandard y 270 MB/s para zlib. El gráfico muestra otra diferencia entre Zstandard y las alternativas: Al utilizar un algoritmo y una implementación, Zstandard permite un ajuste mucho más preciso para cada caso de uso. Esto significa que Zstandard puede competir con algunos de los algoritmos de compresión más rápidos y elevados, manteniendo una ventaja sustancial en la velocidad de descompresión. Estas mejoras se traducen directamente en una transferencia de datos más rápida y menores requisitos de almacenamiento.
En otras palabras, en comparación con zlib, Zstandard escala:
- A la misma relación de compresión, comprime sustancialmente más rápido: ~3-5x.
- A la misma velocidad de compresión, es sustancialmente más pequeño: 10-15 por ciento más pequeño.
- Es casi 2 veces más rápido en la descompresión, independientemente de la relación de compresión; los números de herramientas de línea de comandos muestran una diferencia aún mayor: más de 3x más rápido.
- Se adapta a ratios de compresión mucho más elevados, a la vez que mantiene velocidades de descompresión ultrarrápidas.
Dentro del capó
Zstandard mejora a zlib combinando varias innovaciones recientes y apuntando al hardware moderno:
Memoria
Por diseño, zlib está limitado a una ventana de 32 KB, lo cual era una elección sensata a principios de los 90. Sin embargo, el entorno informático actual puede acceder a mucha más memoria, incluso en entornos móviles e integrados.
Zstandard no tiene ningún límite inherente y puede abordar terabytes de memoria (aunque rara vez lo hace). Por ejemplo, el menor de los 22 niveles utiliza 1 MB o menos. Para la compatibilidad con una amplia gama de sistemas receptores, donde la memoria puede ser limitada, se recomienda limitar el uso de la memoria a 8 MB. Sin embargo, se trata de una recomendación de ajuste, no de una limitación del formato de compresión.
Un formato diseñado para la ejecución en paralelo
Las CPU de hoy en día son muy potentes y pueden emitir varias instrucciones por ciclo, gracias a las múltiples ALU (unidades aritméticas lógicas) y a un diseño de ejecución fuera de orden cada vez más avanzado.
En esencia, significa que si:
a = b1 + b2
c = d1 + d2
entonces tanto a como cse calcularán en paralelo.
Esto sólo es posible si no hay relación entre ellos. Por lo tanto, en este ejemplo:
a = b1 + b2
c = d1 + a
c debe esperar a que a se calcule primero, y sólo entonces comenzará el cálculo de c.
Significa que, para aprovechar las ventajas de la CPU moderna, hay que diseñar un flujo de operaciones con pocas o ninguna dependencia de datos.
Esto se consigue con Zstandard separando los datos en múltiples flujos paralelos. Un decodificador Huffman de nueva generación, Huff0, es capaz de decodificar múltiples símbolos en paralelo con un solo núcleo. Esta ganancia se acumula con el multihilo, que utiliza varios núcleos.
Diseño sin ramificaciones
Las nuevas CPU son más potentes y alcanzan frecuencias muy altas, pero esto sólo es posible gracias a un enfoque multietapa, en el que una instrucción se divide en una ramificación de múltiples pasos. En cada ciclo de reloj, la CPU es capaz de emitir el resultado de múltiples operaciones, dependiendo de las ALUs disponibles. Cuantas más ALU se utilicen, más trabajo hará la CPU y, por tanto, más rápida será la compresión. Mantener las ALU alimentadas con trabajo es crucial para el rendimiento de la CPU moderna.
Esto resulta ser difícil. Considere la siguiente situación simple:
if (condition) doSomething() else doSomethingElse()Cuando se encuentra con esto, la CPU no sabe qué hacer, ya que depende del valor de condition. Una CPU cautelosa esperaría el resultado de condition antes de trabajar en cualquiera de las dos ramas, lo que sería un gran desperdicio.
Las CPUs de hoy en día apuestan. Lo hacen de forma inteligente, gracias a un predictor de rama, que les indica en esencia el resultado más probable de evaluar condition. Cuando la apuesta es correcta, el pipeline permanece lleno y las instrucciones se emiten continuamente. Cuando la apuesta es incorrecta (una predicción errónea), la CPU tiene que detener todas las operaciones iniciadas especulativamente, volver a la rama y tomar la otra dirección. Esto se llama pipeline flush, y es extremadamente costoso en las CPUs modernas.
Hace 25 años, el pipeline flush no era un problema. Hoy en día, es tan importante que es esencial diseñar formatos compatibles con algoritmos sin ramas. Como ejemplo, veamos una actualización de flujo de bits:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Como puedes ver, la versión sin ramas tiene una carga de trabajo predecible, sin ninguna condición. La CPU siempre hará el mismo trabajo, y ese trabajo nunca se desecha debido a un error de predicción. En cambio, la versión clásica hace menos trabajo cuando (nbBitsUsed < 8). Pero la prueba en sí misma no es gratuita, y cada vez que la prueba se adivina de forma incorrecta, resulta en un vaciado completo de la tubería, que cuesta más que el trabajo realizado por la versión sin rama.
Como puedes adivinar, este efecto secundario tiene impactos en la forma en que los datos son empaquetados, leídos y decodificados. Zstandard ha sido creado para ser amigable con los algoritmos sin ramas, especialmente dentro de los bucles críticos.
Entropía de Estado Finito: Un compresor probabilístico de nueva generación
En la compresión, los datos se transforman primero en un conjunto de símbolos (la etapa de modelado), y luego estos símbolos se codifican utilizando un número mínimo de bits. Esta segunda etapa se denomina etapa de entropía, en recuerdo de Claude Shannon, que calcula con precisión el límite de compresión de un conjunto de símbolos con probabilidades dadas (llamado «límite de Shannon»). El objetivo es acercarse a este límite utilizando el menor número posible de recursos de la CPU.
Un algoritmo muy común es la codificación Huffman, en uso dentro de Deflate. Da el mejor código prefijo posible, asumiendo que cada símbolo se describe con un número natural de bits (1 bit, 2 bits…). Esto funciona muy bien en la práctica, pero el límite de los números naturales significa que es imposible alcanzar altos ratios de compresión, porque un símbolo consume necesariamente al menos 1 bit.
Un método mejor es la llamada codificación aritmética, que puede acercarse arbitrariamente al límite de Shannon -log2(P), consumiendo por tanto bits fraccionarios por símbolo. Esto se traduce en una mejor relación de compresión cuando las probabilidades son altas, pero también utiliza más potencia de la CPU. En la práctica, incluso los codificadores aritméticos optimizados luchan por la velocidad, especialmente en el lado de la descompresión, que requiere divisiones con un resultado predecible (por ejemplo, no un punto flotante) y que resulta ser lento.
La Entropía de Estado Finito se basa en una nueva teoría llamada ANS (Sistema Numérico Asimétrico) de Jarek Duda. La Entropía de Estado Finito es una variante que precomputa muchos pasos de codificación en tablas, lo que da como resultado un códec de entropía tan preciso como la codificación aritmética, utilizando sólo sumas, búsquedas en tablas y desplazamientos, lo que supone aproximadamente el mismo nivel de complejidad que Huffman. También reduce la latencia para acceder al siguiente símbolo, ya que es inmediatamente accesible desde el valor de estado, mientras que Huffman requiere una operación previa de decodificación del flujo de bits. Explicar cómo funciona está fuera del alcance de este post, pero si te interesa, hay una serie de artículos que detallan su funcionamiento interno.
Modelado de código de repetición
El modelado de código de repetición comprime eficazmente los datos estructurados, que presentan secuencias de contenido casi equivalente, que se diferencian por sólo uno o unos pocos bytes. Este método no es nuevo, pero se utilizó por primera vez después de la publicación de Deflate, por lo que no existe dentro de zlib/gzip.
La eficiencia del modelado de repcode depende en gran medida del tipo de datos que se comprime, oscilando entre una mejora de la compresión de uno a dos dígitos. Estas mejoras combinadas se suman a una experiencia de compresión mejor y más rápida, ofrecida dentro de la biblioteca Zstandard.
Zstandard en la práctica
Como se mencionó anteriormente, hay varios casos de uso típicos de la compresión. Para que un algoritmo sea convincente, tiene que ser extraordinariamente bueno en un caso de uso específico, como la compresión de texto legible por humanos, o muy bueno en muchos casos de uso diversos. Zstandard adopta este último enfoque. Una forma de pensar en los casos de uso es cuántas veces se puede descomprimir un dato específico. Zstandard tiene ventajas en todos estos casos.
Muchas veces. Para los datos procesados muchas veces, la velocidad de descompresión y la capacidad de optar por una relación de compresión muy alta sin comprometer la velocidad de descompresión es ventajosa. El almacenamiento del gráfico social en Facebook, por ejemplo, se lee repetidamente a medida que usted y sus amigos interactúan con el sitio. Fuera de Facebook, los ejemplos de cuando los datos necesitan ser descomprimidos muchas veces incluyen archivos descargados de un servidor, como el código fuente del kernel de Linux o los RPMs instalados en los servidores, el JavaScript y el CSS utilizados por una página web, o la ejecución de miles de MapReduces sobre los datos en un almacén de datos.
Sólo una vez. En el caso de los datos comprimidos una sola vez, especialmente para su transmisión a través de una red, la compresión es un momento fugaz en el flujo de datos. Cuanto menor sea la sobrecarga en el servidor, éste podrá atender más peticiones por segundo. La menor sobrecarga en el cliente significa que se puede actuar sobre los datos más rápidamente. Esto suele ocurrir en situaciones cliente/servidor en las que los datos son únicos para el cliente, como la respuesta de un servidor web que es personalizada, por ejemplo, los datos que se utilizan para procesar cuando se recibe una nota de un amigo en Messenger. El resultado neto es que tu dispositivo móvil carga las páginas más rápido, utiliza menos batería y consume menos de tu plan de datos. Zstandard, en particular, se adapta a los escenarios móviles mucho mejor que otros algoritmos debido a cómo maneja los datos pequeños.
Posiblemente nunca. Aunque parezca contradictorio, a menudo ocurre que un dato -como las copias de seguridad o los archivos de registro- no se descomprime nunca, pero puede leerse si se necesita. Para este tipo de datos, la compresión debe ser rápida, hacer que los datos sean pequeños (con una compensación de tiempo/espacio adecuada a la situación) y quizás almacenar una suma de comprobación, pero por lo demás ser invisible. En las raras ocasiones en las que es necesario descomprimir, no se quiere que la compresión ralentice el caso de uso operativo. La descompresión rápida es beneficiosa porque a menudo es una pequeña parte de los datos (como un archivo específico en la copia de seguridad o un mensaje en un archivo de registro) que necesita ser encontrado rápidamente.
En todos estos casos, Zstandard aporta la capacidad de comprimir y descomprimir muchas veces más rápido que gzip, con los datos comprimidos resultantes siendo más pequeños.
Datos pequeños
Hay otro caso de uso para la compresión que recibe menos atención pero puede ser bastante importante: los datos pequeños. Se trata de patrones de uso en los que los datos se producen y consumen en pequeñas cantidades, como los mensajes JSON entre un servidor web y el navegador (normalmente cientos de bytes) o las páginas de datos en una base de datos (unos pocos kilobytes).
Las bases de datos proporcionan un caso de uso interesante. Sistemas como MySQL, PostgreSQL y MongoDB almacenan datos destinados al acceso en tiempo real. Las recientes ventajas del hardware, especialmente en torno a la proliferación de dispositivos flash (SSD), han cambiado fundamentalmente el equilibrio entre el tamaño y el rendimiento: ahora vivimos en un mundo en el que las IOP (operaciones de entrada/salida por segundo) son bastante elevadas, pero la capacidad de nuestros dispositivos de almacenamiento es inferior a la que había cuando los discos duros dominaban el centro de datos.
Además, la tecnología flash tiene una propiedad interesante en cuanto a la resistencia a la escritura: después de miles de escrituras en la misma sección del dispositivo, esa sección ya no puede aceptar escrituras, lo que a menudo hace que el dispositivo quede fuera de servicio. Por lo tanto, es natural buscar formas de reducir la cantidad de datos que se escriben, ya que puede significar más datos por servidor y quemar el dispositivo a un ritmo más lento. La compresión de datos es una estrategia para esto, y las bases de datos también suelen estar optimizadas para el rendimiento, lo que significa que el rendimiento de lectura y escritura son igualmente importantes.
Sin embargo, hay una complicación para usar la compresión de datos con las bases de datos. A las bases de datos les gusta acceder a los datos de forma aleatoria, mientras que la mayoría de los casos típicos de uso de la compresión leen un archivo completo en orden lineal. Esto es un problema porque la compresión de datos funciona esencialmente prediciendo el futuro basándose en el pasado: los algoritmos miran los datos secuencialmente y predicen lo que podrían ver en el futuro. Cuanto más precisas sean las predicciones, más pequeños serán los datos.
Cuando se comprimen datos pequeños, como las páginas de una base de datos o los diminutos documentos JSON que se envían al dispositivo móvil, simplemente no hay mucho «pasado» que utilizar para predecir el futuro. Los algoritmos de compresión han intentado solucionar este problema mediante el uso de diccionarios precompartidos para dar un impulso efectivo. Esto se hace compartiendo previamente un conjunto estático de datos «pasados» como semilla para la compresión.
Zstandard se basa en este enfoque con algoritmos y API altamente optimizados para la compresión de diccionarios. Además, Zstandard incluye herramientas (zstd --train)para crear fácilmente diccionarios para aplicaciones personalizadas y disposiciones para registrar diccionarios estándar para compartirlos con comunidades más amplias. Mientras que la compresión varía en función de las muestras de datos, la compresión de datos pequeños puede oscilar entre 2 y 5 veces mejor que la compresión sin diccionarios.
Diccionarios en acción
Aunque puede ser difícil jugar con un diccionario en el contexto de una base de datos en funcionamiento (requiere modificaciones significativas en la base de datos, después de todo), puedes ver diccionarios en acción con otros tipos de datos pequeños. JSON, la lingua franca de los datos pequeños en el mundo moderno, tiende a ser registros pequeños y repetitivos. Hay innumerables conjuntos de datos públicos disponibles; para el propósito de esta demostración, utilizaremos el conjunto de datos «usuario» de GitHub, disponible a través de HTTP. He aquí un ejemplo de entrada de este conjunto de datos:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }Como puedes ver, hay bastantes repeticiones aquí – ¡podemos comprimirlas muy bien! Pero cada usuario ocupa algo menos de 1 KB, y la mayoría de los algoritmos de compresión necesitan más datos para estirar las piernas. Un conjunto de 1.000 usuarios necesita aproximadamente 850 KB para almacenarse sin comprimir. Aplicando ingenuamente gzip u zstd individualmente a cada archivo, esto se reduce a poco más de 300 KB; ¡no está mal! Pero si creamos un diccionario único y precompartido, con zstd el tamaño se reduce a 122 KB, con lo que el ratio de compresión original pasa de 2,8x a 6,9. Esta es una mejora significativa, disponible fuera de la caja con zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Elegir un nivel de compresión
Como se muestra arriba, Zstandard proporciona un número sustancial de niveles. Esta personalización es poderosa pero lleva a elecciones difíciles. La mejor manera de decidir es revisar tus datos y medir, decidiendo qué compensaciones quieres hacer. En Facebook, consideramos que el nivel 3 por defecto es adecuado para muchos casos de uso, pero de vez en cuando lo ajustamos ligeramente dependiendo de cuál sea nuestro cuello de botella (a menudo intentamos saturar una conexión de red o un disco); otras veces, nos importa más el tamaño almacenado y utilizamos un nivel más alto.
En definitiva, para obtener los resultados más ajustados a tus necesidades, tendrás que tener en cuenta tanto el hardware que utilizas como los datos que te interesan: no hay prescripciones rígidas que puedan hacerse sin contexto. En caso de duda, sin embargo, o bien seguir con el nivel predeterminado de 3 o algo de la gama de 6 a 9 para un buen compromiso de la velocidad frente al espacio; guardar el nivel 20 + para los casos en que realmente se preocupan sólo por el tamaño y no sobre la velocidad de compresión.
Probarlo
Zstandard es tanto una herramienta de línea de comandos (zstd) y una biblioteca. Está escrito en C altamente portable, lo que lo hace adecuado para prácticamente todas las plataformas utilizadas hoy en día – ya sean los servidores que dirigen su negocio, su ordenador portátil, o incluso el teléfono en su bolsillo. Puedes obtenerlo de nuestro repositorio de github, compilarlo con un simple make install, y empezar a usarlo como lo harías con gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Como es de esperar, puedes usarlo como parte de una cadena de comandos, por ejemplo, para hacer una copia de seguridad de tu base de datos MySQL crítica:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstEl comando tar soporta diferentes implementaciones de compresión out-of-box, así que una vez que instales Zstandard, puedes trabajar inmediatamente con tarballs comprimidos con Zstandard. Aquí hay un ejemplo simple que muestra su uso con tar y la diferencia de velocidad en comparación con gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalMás allá del uso de la línea de comandos, están las APIs, documentadas en los archivos de cabecera en el repositorio (empieza aquí para una visión general de las APIs). También incluimos una API envolvente compatible con zlib (libWrapper) para facilitar la integración con herramientas que ya tienen interfaces zlib. Por último, incluimos una serie de ejemplos, tanto de uso básico como de uso más avanzado, como diccionarios y streaming, también en el repositorio de GitHub.
Más por venir
Aunque hemos llegado a la versión 1.0 y consideramos que Zstandard está listo para todo tipo de uso en producción, no hemos terminado. En futuras versiones:
- Compresión multihilo en la línea de comandos para un rendimiento aún más rápido en grandes conjuntos de datos, similar a la herramienta pigz para zlib.
- Nuevos niveles de compresión, en ambas direcciones, que permiten una compresión aún más rápida y ratios más altos.
- Un conjunto predefinido y mantenido por la comunidad de diccionarios de compresión para conjuntos de datos comunes como JSON, HTML y protocolos de red comunes.
Nos gustaría dar las gracias a todos los colaboradores, tanto de código como de comentarios, que nos han ayudado a llegar a la versión 1.0. Esto es sólo el principio. Sabemos que para que Zstandard esté a la altura de su potencial, necesitamos tu ayuda. Como se mencionó anteriormente, usted puede probar Zstandard hoy en día mediante la obtención de la fuente o binarios pre-construidos de nuestro proyecto GitHub, o, para los usuarios de Mac, la instalación a través de homebrew (brew install zstd). Nos encantaría recibir cualquier comentario y casos de uso interesantes que tengas, así como enlaces de lenguaje adicionales y ayuda para integrarlo con tus proyectos de código abierto favoritos.
Notas de pie de página
- Aunque la compresión de datos sin pérdidas es el foco de este post, existe un campo relacionado pero muy diferente de la compresión de datos con pérdidas, utilizado principalmente para imágenes, audio y vídeo.
- Deflate, zlib, gzip – tres nombres entrelazados. Deflate es el algoritmo utilizado por las implementaciones de zlib y gzip. Zlib es una biblioteca que proporciona Deflate, y gzip es una herramienta de línea de comandos que utiliza zlib para desinflar los datos, así como la suma de comprobación. Este checksumming puede tener una sobrecarga significativa.
- Todos los benchmarks se realizaron en un Intel E5-2678 v3 corriendo a 2,5 GHz en una máquina Centos 7. Las herramientas de línea de comandos (
zstdygzip) fueron construidas con el sistema GCC, 4.8.5. Los benchmarks de algoritmos realizados por lzbench fueron construidos con GCC 6.
Deja una respuesta