En este post, vamos a echar un vistazo a los algoritmos de aprendizaje automático más utilizados. Hay una gran variedad de ellos, y es fácil sentirse confundido cuando se escuchan términos como «algoritmos de aprendizaje basados en instancias» y «perceptrón».
Por lo general, todos los algoritmos de aprendizaje automático se dividen en grupos basados en su estilo de aprendizaje, su función o los problemas que resuelven. En este post, encontrarás una clasificación basada en el estilo de aprendizaje. También mencionaré las tareas comunes que estos algoritmos ayudan a resolver.
El número de algoritmos de aprendizaje automático que se utilizan hoy en día es grande, y no mencionaré el 100% de ellos. Sin embargo, me gustaría ofrecer una visión general de los más utilizados.
- Algoritmos de aprendizaje supervisado
- Algoritmos de clasificación
- Naive Bayes
- Multinomial Naive Bayes
- Regresión logística
- Árboles de decisión
- SVM (Support Vector Machine)
- Algoritmos de regresión
- Regresión lineal
- Algoritmos de aprendizaje no supervisado
- Clustering
- El clustering de k-means
- K-nearest neighbor
- Reducción de la dimensionalidad
- Aprendizaje de reglas de asociación
- Aprendizaje por refuerzo
- Aprendizaje Q
- Aprendizaje por conjuntos
- Bagging
- Boosting
- Bosque aleatorio
- Apilamiento
- Redes neuronales
- Conclusión
Algoritmos de aprendizaje supervisado

Si no estás familiarizado con términos como «aprendizaje supervisado» y «aprendizaje no supervisado», echa un vistazo a nuestro post AI vs. ML donde se trata este tema en detalle. Ahora, vamos a familiarizarnos con los algoritmos.
Algoritmos de clasificación
Naive Bayes

Los algoritmos bayesianos son una familia de clasificadores probabilísticos utilizados en ML basados en la aplicación del teorema de Bayes.
El clasificador Naive Bayes fue uno de los primeros algoritmos utilizados para el aprendizaje automático. Es adecuado para la clasificación binaria y multiclase y permite hacer predicciones y pronosticar datos basándose en resultados históricos. Un ejemplo clásico son los sistemas de filtrado de spam que utilizaron Naive Bayes hasta 2010 y mostraron resultados satisfactorios. Sin embargo, cuando se inventó el envenenamiento bayesiano, los programadores empezaron a pensar en otras formas de filtrar los datos.
Usando el teorema de Bayes, es posible decir cómo la ocurrencia de un evento impacta en la probabilidad de otro evento.
Por ejemplo, este algoritmo calcula la probabilidad de que un determinado correo electrónico sea o no spam basándose en las palabras típicas utilizadas. Las palabras de spam más comunes son «oferta», «pedir ahora» o «ingresos adicionales». Si el algoritmo detecta estas palabras, hay una alta posibilidad de que el correo electrónico sea spam.
Naive Bayes asume que las características son independientes. Por lo tanto, el algoritmo se llama ingenuo.
Multinomial Naive Bayes
Aparte del clasificador Naive Bayes, hay otros algoritmos en este grupo. Por ejemplo, el Bayes ingenuo multinomial, que suele aplicarse para la clasificación de documentos basándose en la frecuencia de ciertas palabras presentes en el documento.
Los algoritmos bayesianos se siguen utilizando para la categorización de textos y la detección de fraudes. También pueden aplicarse para la visión artificial (por ejemplo, la detección de rostros), la segmentación de mercados y la bioinformática.
Regresión logística
Aunque el nombre pueda parecer contraintuitivo, la regresión logística es en realidad un tipo de algoritmo de clasificación.
La regresión logística es un modelo que realiza predicciones utilizando una función logística para encontrar la dependencia entre las variables de salida y de entrada. Statquest hizo un gran video donde explican la diferencia entre regresión lineal y logística tomando como ejemplo ratones obesos.
Árboles de decisión
Un árbol de decisión es una forma sencilla de visualizar un modelo de toma de decisiones en forma de árbol. Las ventajas de los árboles de decisión son que son fáciles de entender, interpretar y visualizar. Además, exigen poco esfuerzo para la preparación de los datos.
Sin embargo, también tienen una gran desventaja. Los árboles pueden ser inestables debido a las más pequeñas variaciones (varianza) de los datos. También es posible crear árboles demasiado complejos que no generalizan bien. Esto se llama sobreajuste. El bagging, el boosting y la regularización ayudan a combatir este problema. Vamos a hablar de ellos más adelante en el post.
Los elementos de cada árbol de decisión son:
- Nodo raíz que hace la pregunta principal. Tiene las flechas que apuntan hacia abajo desde él pero no tiene flechas que apunten hacia él. Por ejemplo, imagine que está construyendo un árbol para decidir qué tipo de pasta debe cenar.
- Subsecciones. Una subsección de un árbol se llama rama o a veces subárbol.
- Nodos de decisión. Son los subnodos del nodo raíz que también pueden dividirse en más nodos. Sus nodos de decisión pueden ser «¿carbonara?» o «¿con champiñones?».
- Nodos de salida o terminales. Estos nodos no se dividen. Representan decisiones o predicciones finales.
También es importante mencionar la división. Este es el proceso de dividir un nodo en subnodos. Por ejemplo, si no eres vegetariano, la carbonara está bien. Pero si lo eres, come pasta con setas. También existe un proceso de eliminación de nodos llamado poda.
Los algoritmos de árboles de decisión se denominan CART (Classification and Regression Trees). Los árboles de decisión pueden trabajar con datos categóricos o numéricos.
- Los árboles de regresión se utilizan cuando las variables tienen valor numérico.
- Los árboles de clasificación se pueden aplicar cuando los datos son categóricos (clases).
Los árboles de decisión son bastante intuitivos de entender y utilizar. Por ello, los diagramas de árbol se aplican comúnmente en una amplia gama de industrias y disciplinas. GreyAtom proporciona una amplia visión de los diferentes tipos de árboles de decisión y sus aplicaciones prácticas.
SVM (Support Vector Machine)
Las máquinas de vectores de apoyo son otro grupo de algoritmos utilizados para tareas de clasificación y, a veces, de regresión. La SVM es excelente porque ofrece resultados bastante precisos con una potencia de cálculo mínima.
El objetivo de la SVM es encontrar un hiperplano en un espacio de N dimensiones (donde N se corresponde con el número de características) que clasifique claramente los puntos de datos. La precisión de los resultados se correlaciona directamente con el hiperplano que elegimos. Debemos encontrar un plano que tenga la máxima distancia entre los puntos de datos de ambas clases.
Este hiperplano se representa gráficamente como una línea que separa una clase de otra. Los puntos de datos que caen en diferentes lados del hiperplano se atribuyen a diferentes clases.
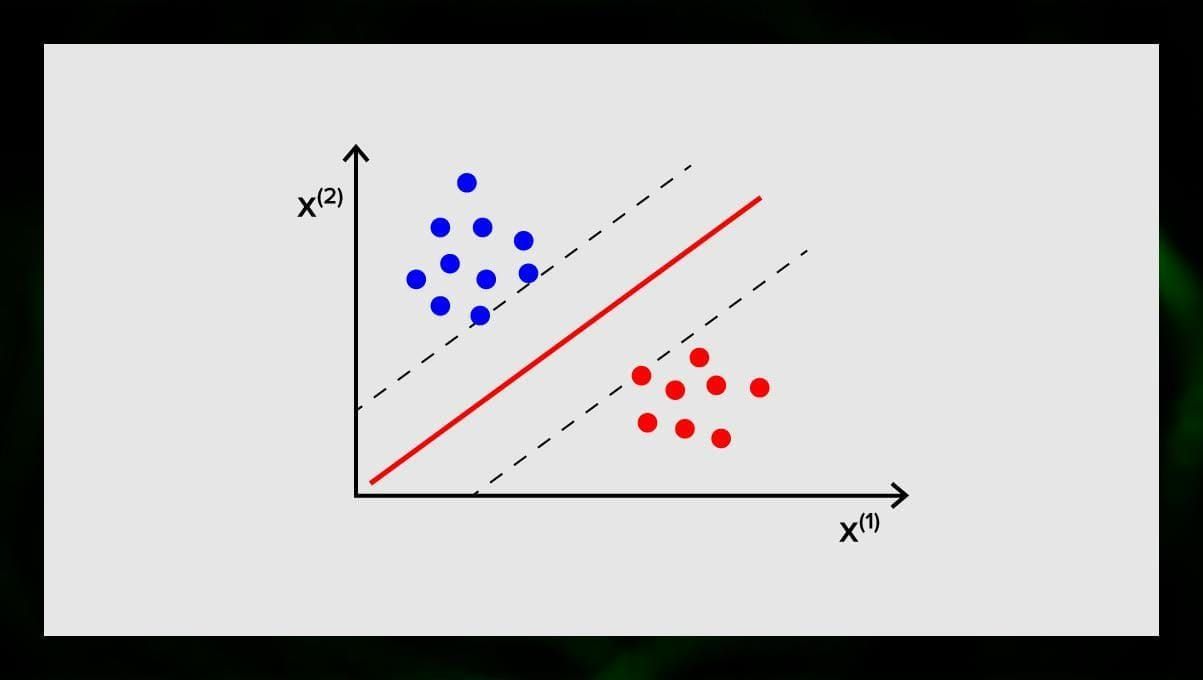
Nótese que la dimensión del hiperplano depende del número de características. Si el número de características de entrada es 2, entonces el hiperplano es sólo una línea. Si el número de características de entrada es 3, entonces el hiperplano se convierte en un plano de dos dimensiones. Resulta difícil dibujar un modelo en un gráfico cuando el número de características es superior a 3. Así que, en este caso, se utilizarán tipos de Kernel para transformarlo en un espacio de 3 dimensiones.
¿Por qué se llama máquina de vectores de soporte? Los vectores de soporte son los puntos de datos más cercanos al hiperplano. Influyen directamente en la posición y orientación del hiperplano y nos permiten maximizar el margen del clasificador. La eliminación de los vectores de soporte cambiará la posición del hiperplano. Estos son los puntos que nos ayudan a construir nuestra SVM.
Las SVM se utilizan ahora activamente en el diagnóstico médico para encontrar anomalías, en los sistemas de control de la calidad del aire, para el análisis financiero y las predicciones en el mercado de valores, y el control de fallos de las máquinas en la industria.
Algoritmos de regresión
Los algoritmos de regresión son útiles en la analítica, por ejemplo, cuando se intenta predecir los costes de los valores o las ventas de un producto concreto en un momento determinado.
Regresión lineal
La regresión lineal intenta modelar la relación entre variables ajustando una ecuación lineal a los datos observados.
Hay variables explicativas y dependientes. Las variables dependientes son cosas que queremos explicar o pronosticar. Las explicativas, como sigue por el nombre, explican algo. Si quieres construir una regresión lineal, asumes que hay una relación lineal entre tus variables dependientes e independientes. Por ejemplo, existe una correlación entre los metros cuadrados de una casa y su precio o la densidad de población y los locales de kebab de la zona.
Una vez que hagas esa suposición, lo siguiente que tienes que hacer es averiguar la relación lineal concreta. Tendrás que encontrar una ecuación de regresión lineal para un conjunto de datos. El último paso es calcular el residuo.
Nota: Cuando la regresión dibuja una línea recta, se llama lineal, cuando es una curva – polinómica.
Algoritmos de aprendizaje no supervisado

Ahora hablemos de los algoritmos que son capaces de encontrar patrones ocultos en datos no etiquetados.
Clustering
Clustering significa que estamos dividiendo los inputs en grupos según el grado de similitud entre ellos. La agrupación suele ser uno de los pasos para construir un algoritmo más complejo. Es más sencillo estudiar cada grupo por separado y construir un modelo basado en sus características, que trabajar con todo a la vez. La misma técnica se utiliza constantemente en marketing y ventas para dividir a todos los clientes potenciales en grupos.
Los algoritmos de clustering más comunes son k-means clustering y k-nearest neighbor.
El clustering de k-means
El clustering de k-means divide el conjunto de elementos del espacio vectorial en un número predefinido de clusters k. Sin embargo, un número incorrecto de clusters invalidará todo el proceso, por lo que es importante probarlo con números variables de clusters. La idea principal del algoritmo k-means es que los datos se dividen aleatoriamente en clusters, y después se recalcula iterativamente el centro de cada cluster obtenido en el paso anterior. A continuación, los vectores se dividen de nuevo en clusters. El algoritmo se detiene cuando en algún momento no hay cambios en los clústeres después de una iteración.
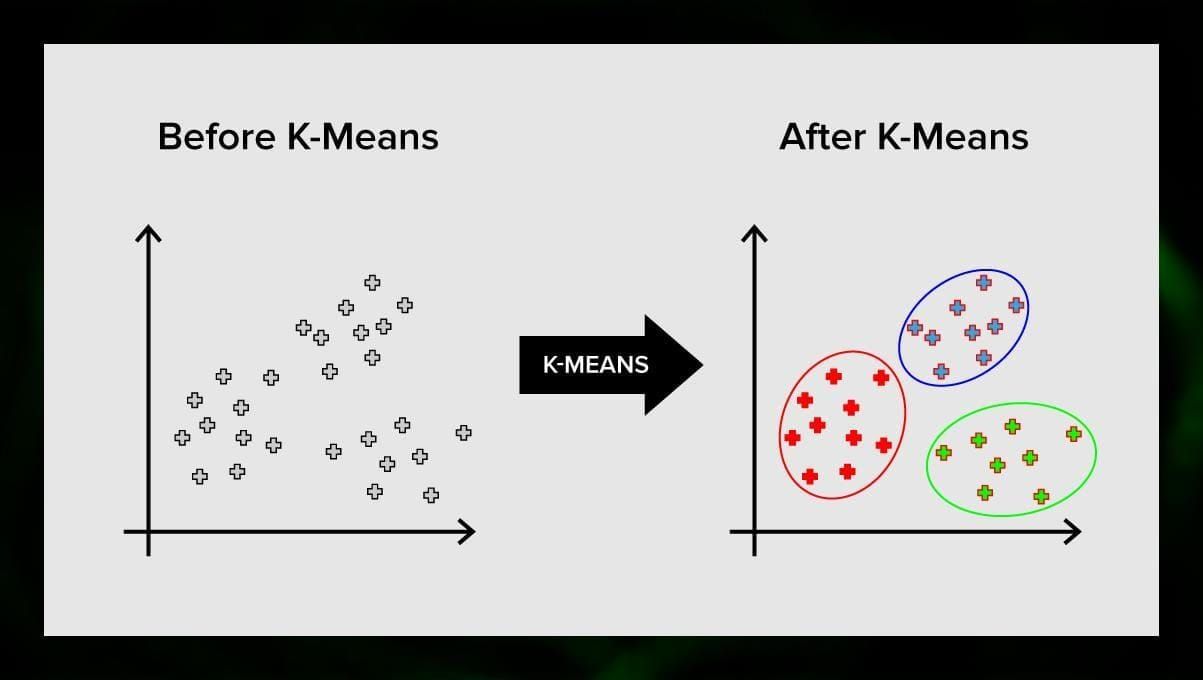
Este método puede aplicarse para resolver problemas cuando los clústeres son distintos o pueden separarse unos de otros fácilmente, sin que los datos se solapen.
K-nearest neighbor
kNN significa k-nearest neighbor. Se trata de uno de los algoritmos de clasificación más sencillos que a veces se utiliza en tareas de regresión.
Para entrenar el clasificador, hay que disponer de un conjunto de datos con clases predefinidas. La clasificación se realiza manualmente con la participación de especialistas en el área estudiada. Utilizando este algoritmo, es posible trabajar con múltiples clases o aclarar las situaciones en las que las entradas pertenecen a más de una clase.
El método se basa en la suposición de que las etiquetas similares corresponden a objetos cercanos en el espacio del vector de atributos.
Los sistemas de software modernos utilizan kNN para el reconocimiento de patrones visuales, por ejemplo, para escanear y detectar paquetes ocultos en el fondo del carrito en la caja (por ejemplo, AmazonGo). Los algoritmos de kNN analizan todos los datos y detectan patrones inusuales que indican actividades sospechosas.
Reducción de la dimensionalidad
El análisis de componentes principales (PCA) es una técnica importante que hay que entender para resolver eficazmente los problemas relacionados con el ML.
Imagina que tienes muchas variables que considerar. Por ejemplo, necesita agrupar las ciudades en tres grupos: buenas para vivir, malas para vivir y más o menos. ¿Cuántas variables tiene que considerar? Probablemente, muchas. ¿Conoce las relaciones entre ellas? No. Entonces, ¿cómo puede tomar todas las variables que ha recogido y centrarse sólo en unas pocas que son las más importantes?
En términos técnicos, quiere «reducir la dimensión de su espacio de características». Al reducir la dimensión de su espacio de características, usted logra obtener menos relaciones entre las variables a considerar y es menos probable que sobreajuste su modelo.
Hay muchas maneras de lograr la reducción de la dimensionalidad, pero la mayoría de estas técnicas caen en una de dos clases:
- Eliminación de características;
- Extracción de características.
La eliminación de características significa que usted reduce el número de características mediante la eliminación de algunas de ellas. Las ventajas de este método son que es simple y mantiene la interpretabilidad de sus variables. Como desventaja, sin embargo, se obtiene cero información de las variables que se ha decidido eliminar.
La extracción de características evita este problema. El objetivo al aplicar este método es extraer un conjunto de características del conjunto de datos dado. La extracción de características tiene como objetivo reducir el número de características en un conjunto de datos mediante la creación de nuevas características basadas en las existentes (y luego descartando las características originales). El nuevo conjunto reducido de características tiene que crearse de forma que sea capaz de resumir la mayor parte de la información contenida en el conjunto original de características.
El análisis de componentes principales es un algoritmo para la extracción de características. combina las variables de entrada de una forma específica, y entonces es posible descartar las variables «menos importantes» mientras se conservan las partes más valiosas de todas las variables.
Uno de los posibles usos de PCA es cuando las imágenes del conjunto de datos son demasiado grandes. Una representación de características reducida ayuda a abordar rápidamente tareas como la comparación y la recuperación de imágenes.
Aprendizaje de reglas de asociación
Apriori es uno de los algoritmos de búsqueda de reglas de asociación más populares. Es capaz de procesar grandes cantidades de datos en un periodo de tiempo relativamente pequeño.
La cuestión es que las bases de datos de muchos proyectos hoy en día son muy grandes, llegando a gigabytes y terabytes. Y seguirán creciendo. Por tanto, se necesita un algoritmo eficaz y escalable para encontrar reglas asociativas en poco tiempo. Apriori es uno de estos algoritmos.
Para poder aplicar el algoritmo, es necesario preparar los datos, convirtiéndolos todos a la forma binaria y cambiando su estructura de datos.
Normalmente, se opera este algoritmo en una base de datos que contiene un gran número de transacciones, por ejemplo, en una base de datos que contiene información sobre todos los artículos que los clientes han comprado en un supermercado.
Aprendizaje por refuerzo

El aprendizaje por refuerzo es uno de los métodos de aprendizaje automático que ayuda a enseñar a la máquina a interactuar con un determinado entorno. En este caso, el entorno (por ejemplo, en un videojuego) sirve de profesor. Proporciona retroalimentación a las decisiones tomadas por el ordenador. Basándose en esta recompensa, la máquina aprende a tomar el mejor curso de acción. Recuerda a la forma en que los niños aprenden a no tocar una sartén caliente: probando y sintiendo dolor.
Desglosando este proceso, implica estos sencillos pasos:
- El ordenador observa el entorno;
- Elige alguna estrategia;
- Actúa de acuerdo con esta estrategia;
- Recibe una recompensa o una penalización;
- Aprende de esta experiencia y refina la estrategia;
- Repite hasta encontrar la estrategia óptima.
Aprendizaje Q
Hay un par de algoritmos que se pueden utilizar para el aprendizaje por refuerzo. Uno de los más comunes es el Q-learning.
El Q-learning es un algoritmo de aprendizaje por refuerzo sin modelo. El aprendizaje Q se basa en la remuneración recibida del entorno. El agente forma una función de utilidad Q, que posteriormente le da la oportunidad de elegir una estrategia de comportamiento, y tener en cuenta la experiencia de las interacciones anteriores con el entorno.
Una de las ventajas del aprendizaje Q es que es capaz de comparar la utilidad esperada de las acciones disponibles sin formar modelos del entorno.
Aprendizaje por conjuntos

El aprendizaje por conjuntos es el método de resolver un problema construyendo múltiples modelos de ML y combinándolos. El aprendizaje por conjuntos se utiliza principalmente para mejorar el rendimiento de los modelos de clasificación, predicción y aproximación de funciones. Otras aplicaciones del aprendizaje de conjuntos incluyen la comprobación de la decisión tomada por el modelo, la selección de características óptimas para la construcción de modelos, el aprendizaje incremental y el aprendizaje no estacionario.
A continuación se presentan algunos de los algoritmos de aprendizaje de conjuntos más comunes.
Bagging
Bagging significa agregación bootstrap. Es uno de los primeros algoritmos de conjunto, con un rendimiento sorprendentemente bueno. Para garantizar la diversidad de los clasificadores, utiliza réplicas bootstrap de los datos de entrenamiento. Esto significa que se extraen aleatoriamente diferentes subconjuntos de datos de entrenamiento -con reemplazo- del conjunto de datos de entrenamiento. Cada subconjunto de datos de entrenamiento se utiliza para entrenar un clasificador diferente del mismo tipo. A continuación, se pueden combinar los clasificadores individuales. Para ello, es necesario realizar una votación por mayoría simple de sus decisiones. La clase asignada por la mayoría de los clasificadores es la decisión del conjunto.
Boosting
Este grupo de algoritmos de conjunto es similar al bagging. Boosting también utiliza una variedad de clasificadores para remuestrear los datos, y luego elige la versión óptima por votación mayoritaria. En el boosting, se entrenan iterativamente clasificadores débiles para ensamblarlos en un clasificador fuerte. Cuando se añaden los clasificadores, se les suele atribuir unos pesos, que describen la precisión de sus predicciones. Después de añadir un clasificador débil al conjunto, se recalculan los pesos. Las entradas incorrectamente clasificadas ganan más peso, y las instancias correctamente clasificadas pierden peso. Así, el sistema se centra más en los ejemplos en los que se obtuvo una clasificación errónea.
Bosque aleatorio
Los bosques aleatorios o bosques de decisión aleatorios son un método de aprendizaje por conjuntos para la clasificación, la regresión y otras tareas. Para construir un bosque aleatorio, es necesario entrenar una multitud de árboles de decisión en muestras aleatorias de datos de entrenamiento. La salida del bosque aleatorio es el resultado más frecuente entre los árboles individuales. Los bosques de decisión aleatorios combaten con éxito el sobreajuste debido a la naturaleza _aleatoria_ del algoritmo.
Apilamiento
El apilamiento es una técnica de aprendizaje de conjunto que combina múltiples modelos de clasificación o regresión a través de un metaclasificador o un metarregresor. Los modelos de nivel básico se entrenan a partir de un conjunto de entrenamiento completo y, a continuación, el metamodelo se entrena con las salidas de los modelos de nivel básico como características.
Redes neuronales
Una red neuronal es una secuencia de neuronas conectadas por sinapsis, que recuerda a la estructura del cerebro humano. Sin embargo, el cerebro humano es aún más complejo.
Lo bueno de las redes neuronales es que pueden utilizarse básicamente para cualquier tarea, desde el filtrado de spam hasta la visión por ordenador. Sin embargo, normalmente se aplican para la traducción automática, la detección de anomalías y la gestión de riesgos, el reconocimiento del habla y la generación del lenguaje, el reconocimiento de caras, etc.
Una red neuronal está formada por neuronas, o nodos. Cada una de estas neuronas recibe datos, los procesa y luego los transfiere a otra neurona.
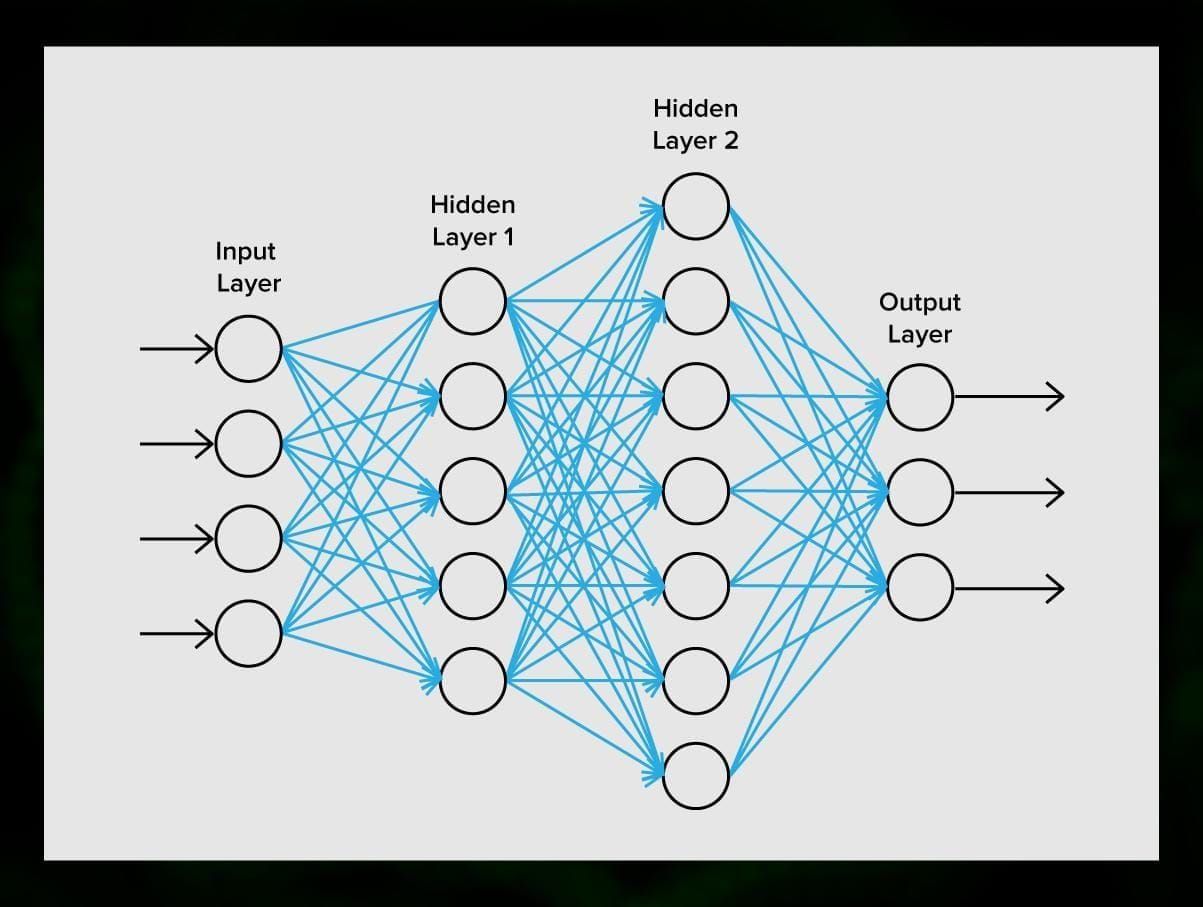
Cada neurona procesa las señales de la misma manera. Pero, ¿cómo se consigue entonces un resultado diferente? Las sinapsis que conectan las neuronas entre sí son las responsables. Cada neurona es capaz de tener muchas sinapsis que atenúan o amplifican la señal. Además, las neuronas son capaces de cambiar sus características con el tiempo. Al elegir los parámetros correctos de la sinapsis, podremos obtener los resultados correctos de la conversión de la información de entrada en la salida.
Hay muchos tipos diferentes de NN:
- Las redes neuronales de avance (FF o FFNN) y los perceptrones § son muy directos, no hay bucles ni ciclos en la red. En la práctica, este tipo de redes se utilizan raramente, pero a menudo se combinan con otros tipos para obtener otras nuevas.
- Una red de Hopfield (HN) es una red neuronal totalmente conectada con una matriz simétrica de enlaces. Una red de este tipo suele llamarse red de memoria asociativa. Al igual que una persona que al ver una mitad de la tabla, puede imaginar la segunda mitad, esta red, al recibir una tabla con ruido, la restablece en su totalidad.
- Las redes neuronales convolucionales (CNN) y las redes neuronales convolucionales profundas (DCNN) son muy diferentes de otros tipos de redes. Suelen utilizarse para tareas de procesamiento de imágenes, audio o vídeo. Una forma típica de aplicar las CNN es clasificar imágenes.
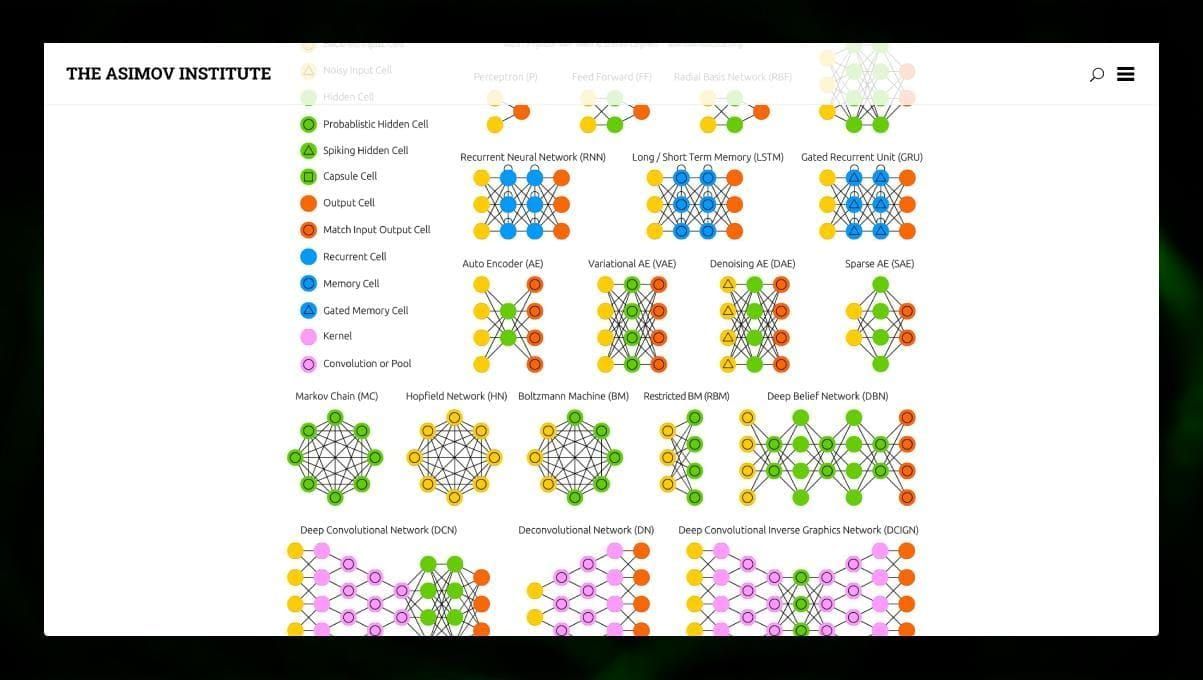
Es interesante observar muchos tipos diferentes de redes neuronales. Es posible hacerlo en el zoo de las NN.
Conclusión
Este post es una amplia visión de los diferentes algoritmos de ML, pero aún queda mucho por decir. Permanece atento a nuestro Twitter, Facebook y Medium para más guías y posts sobre las apasionantes posibilidades del aprendizaje automático.
Deja una respuesta