Mennesker skaber, deler og lagrer data i et hurtigere tempo end nogensinde før. Når det gælder innovation i forbindelse med lagring og overførsel af disse data, gør vi på Facebook ikke kun fremskridt inden for hardware – f.eks. større harddiske og hurtigere netværksudstyr – men også inden for software. Software hjælper med databehandlingen ved hjælp af komprimering, som koder oplysninger, f.eks. tekst, billeder og andre former for digitale data, ved hjælp af færre bits end originalen. Disse mindre filer optager mindre plads på harddiskene og overføres hurtigere til andre systemer. Der er dog en modydelse ved at komprimere og dekomprimere oplysninger: tid. Jo mere tid der bruges på at komprimere til en mindre fil, jo langsommere er det at behandle dataene.
I dag er den regerende datakomprimeringsstandard Deflate, den centrale algoritme i Zip, gzip og zlib . I to årtier har den givet en imponerende balance mellem hastighed og plads, og som følge heraf anvendes den i næsten alle moderne elektroniske enheder (og, ikke tilfældigvis, bruges den til at overføre hver eneste byte i netop det blogindlæg, du læser). I årenes løb har andre algoritmer tilbudt enten bedre komprimering eller hurtigere komprimering, men sjældent begge dele. Vi mener, at vi har ændret dette.
Vi er glade for at kunne annoncere Zstandard 1.0, en ny komprimeringsalgoritme og implementering, der er designet til at skalere med moderne hardware og komprimere mindre og hurtigere. Zstandard kombinerer nylige kompressionsgennembrud, såsom Finite State Entropy, med et design, der fokuserer på ydeevne – og optimerer derefter implementeringen til de unikke egenskaber ved moderne CPU’er. Som følge heraf forbedrer den de kompromiser, som andre komprimeringsalgoritmer foretager, og den har et bredt anvendelsesområde med en meget høj dekomprimeringshastighed. Zstandard, der nu er tilgængelig under BSD-licensen, er designet til at blive brugt i næsten alle tabsfri komprimeringsscenarier, herunder mange, hvor de nuværende algoritmer ikke kan anvendes.
- Sammenligning af kompression
- Skalering
- Under motorhjelmen
- Hukommelse
- Et format designet til parallel udførelse
- Branchless design
- Finite State Entropy: En næste generation af sandsynlighedskompressorer
- Repcode-modellering
- Zstandard i praksis
- Små data
- Dordbøger i aktion
- Valg af komprimeringsniveau
- Afprøv det
- Der kommer mere
Sammenligning af kompression
Der findes tre standardmetrikker til sammenligning af kompressionsalgoritmer og implementeringer:
- Kompressionsforhold: Den oprindelige størrelse (tæller) sammenlignet med den komprimerede størrelse (nævner), målt i data uden enhed som et størrelsesforhold på 1,0 eller derover.
- Komprimeringshastighed: Hvor hurtigt vi kan gøre dataene mindre, målt i MB/s af forbruget af inputdata.
- Dekomprimeringshastighed: Hvor hurtigt vi kan rekonstruere de oprindelige data fra de komprimerede data, målt i MB/s for den hastighed, hvormed data produceres fra komprimerede data.
Den type data, der komprimeres, kan påvirke disse målinger, så mange algoritmer er afstemt til specifikke typer data, f.eks. engelsk tekst, genetiske sekvenser eller rasteriserede billeder. Zstandard er dog ligesom zlib beregnet til komprimering til generelle formål for en række forskellige datatyper. For at repræsentere de algoritmer, som Zstandard forventes at arbejde med, vil vi i dette indlæg bruge Silesia corpus, et datasæt af filer, der repræsenterer de typiske datatyper, der bruges hver dag.
Nogle algoritmer og implementeringer, der er almindeligt anvendte i dag, er zlib, lz4 og xz. Hver af disse algoritmer tilbyder forskellige kompromisser: lz4 sigter mod hastighed, xz sigter mod højere kompressionsforhold, og zlib sigter mod en god balance mellem hastighed og størrelse. Tabellen nedenfor viser de grove afvejninger af algoritmernes standardkompressionsforhold og hastighed for Silesia-korpus ved at sammenligne algoritmerne pr. lzbench, en ren in-memory benchmark, der er beregnet til at modellere algoritmernes rå ydeevne.
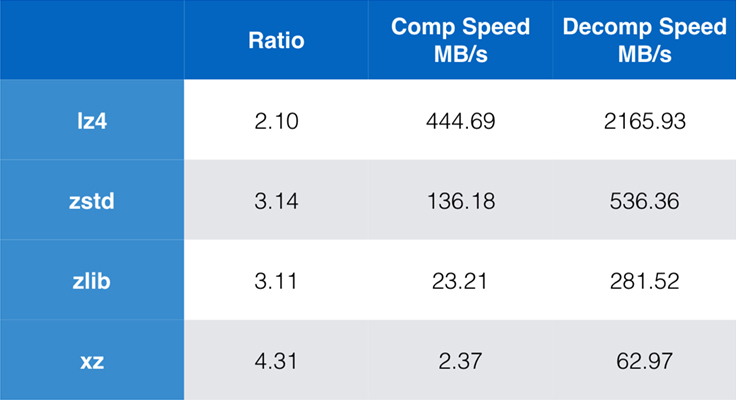
Som skitseret er der ofte drastiske kompromiser mellem hastighed og størrelse. Den hurtigste algoritme, lz4, resulterer i lavere kompressionsforhold; xz, som har det højeste kompressionsforhold, lider under en langsom kompressionshastighed. Zstandard, med standardindstillingen, viser imidlertid betydelige forbedringer i både komprimeringshastighed og dekomprimeringshastighed, samtidig med at den komprimerer med samme komprimeringsforhold som zlib.
Mens ren algoritmeydelse er vigtig, når komprimering er indlejret i et større program, er det yderst almindeligt også at bruge kommandolinjeværktøjer til komprimering – f.eks. til komprimering af logfiler, tarballs eller andre lignende data, der er beregnet til lagring eller overførsel. I disse tilfælde påvirkes ydelsen ofte af overhead, f.eks. checksumming. Dette diagram viser sammenligningen af kommandolinjeværktøjerne gzip og zstd på Centos 7 bygget med systemets standardkompiler.
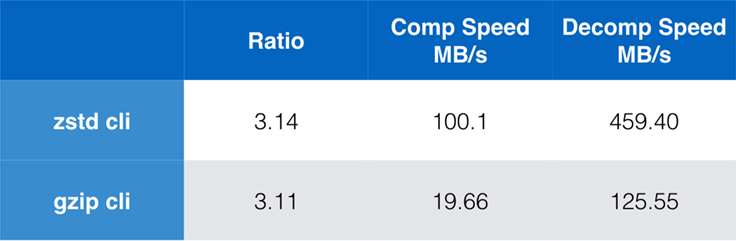
Testene blev hver udført 10 gange, med de mindste tider taget, og blev udført på ramdisk for at undgå overhead i filsystemet. Disse var kommandoerne (som bruger standardkomprimeringsniveauerne for begge værktøjer):
zstd -c -3 silesia.tar > silesia.tar.zst # 67,432,740 byteszstd -d -c silesia.tar.zst > /dev/nullgzip -c -6 silesia.tar > silesia.tar.gz # 68,235,522 bytesgzip -d -c silesia.tar.gz > /dev/nullSkalering
Hvis en algoritme er skalerbar, har den evnen til at tilpasse sig til en lang række forskellige krav, og Zstandard er designet til at udmærke sig i dagens landskab og til at skalere ind i fremtiden. De fleste algoritmer har “niveauer” baseret på afvejninger mellem tid og rum: Jo højere niveauet er, jo større er den komprimering, der opnås med tab af komprimeringshastighed. Zlib tilbyder ni kompressionsniveauer; Zstandard tilbyder i øjeblikket 22, hvilket giver mulighed for fleksible, granulære afvejninger mellem kompressionshastighed og kompressionsforhold for fremtidige data. Vi kan f.eks. bruge niveau 1, hvis hastigheden er vigtigst, og niveau 22, hvis størrelsen er vigtigst.
Nedenfor er der et diagram over den opnåede kompressionshastighed og -forhold for alle niveauer af Zstandard og zlib. X-aksen er en faldende logaritmisk skala i megabyte pr. sekund; y-aksen er det opnåede kompressionsforhold. For at sammenligne algoritmerne kan du vælge en hastighed for at se de forskellige forhold, som algoritmerne opnår ved den pågældende hastighed. På samme måde kan du vælge et forhold og se, hvor hurtigt algoritmerne er, når de opnår dette niveau.
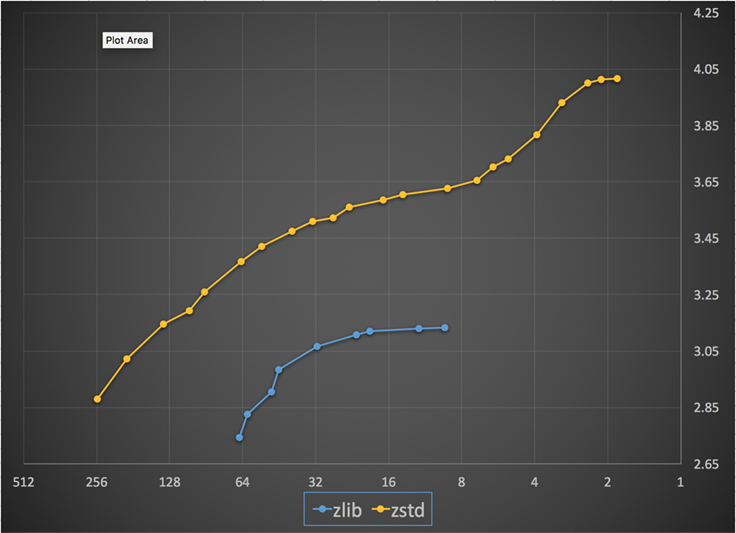
For enhver lodret linje (dvs. komprimeringshastighed) opnår Zstandard et højere komprimeringsforhold. For Silesia-korpus var dekomprimeringshastigheden – uafhængigt af forholdet – ca. 550 MB/s for Zstandard og 270 MB/s for zlib. Diagrammet viser en anden forskel mellem Zstandard og alternativerne: Ved at anvende én algoritme og én implementering giver Zstandard mulighed for en meget mere finkornet indstilling for hvert enkelt anvendelsestilfælde. Det betyder, at Zstandard kan konkurrere med nogle af de hurtigste og højeste komprimeringsalgoritmer og samtidig bevare en betydelig fordel i forhold til dekomprimeringshastighed. Disse forbedringer udmønter sig direkte i hurtigere dataoverførsel og mindre lagerbehov.
Med andre ord, sammenlignet med zlib, skalerer Zstandard:
- Med det samme kompressionsforhold komprimerer den væsentligt hurtigere: ~3-5x.
- Med samme komprimeringshastighed er den væsentligt mindre: 10-15 procent mindre.
- Den er næsten 2x hurtigere ved dekomprimering, uanset komprimeringsforholdet; tallene for kommandolinjeværktøjet viser en endnu større forskel: mere end 3x hurtigere.
- Den skalerer til meget højere kompressionsforhold, samtidig med at den opretholder lynhurtige dekomprimeringshastigheder.
Under motorhjelmen
Zstandard forbedrer zlib ved at kombinere flere nyere innovationer og målrette sig mod moderne hardware:
Hukommelse
Designmæssigt er zlib begrænset til et vindue på 32 KB, hvilket var et fornuftigt valg i begyndelsen af 90’erne. Men nutidens computermiljø kan få adgang til meget mere hukommelse – selv i mobile og indlejrede miljøer.
Zstandard har ingen iboende begrænsning og kan adressere terabyte af hukommelse (selv om det sjældent sker). F.eks. bruger de nederste af de 22 niveauer 1 MB eller mindre. For at opnå kompatibilitet med en bred vifte af modtagersystemer, hvor hukommelsen kan være begrænset, anbefales det at begrænse hukommelsesforbruget til 8 MB. Dette er dog en tuninganbefaling og ikke en begrænsning af komprimeringsformatet.
Et format designet til parallel udførelse
Der er tale om meget kraftfulde CPU’er, som i dag kan udstede flere instruktioner pr. cyklus takket være flere ALU’er (aritmetiske logiske enheder) og et stadig mere avanceret design til udførelse uden for rækkefølge.
I det væsentlige betyder det, at hvis:
a = b1 + b2
c = d1 + d2
så vil både a og c blive beregnet parallelt.
Dette er kun muligt, hvis der ikke er nogen sammenhæng mellem dem. Derfor skal i dette eksempel:
a = b1 + b2
c = d1 + a
c vente på, at a først bliver beregnet, og først derefter vil c beregningen starte.
Det betyder, at man for at udnytte den moderne CPU skal designe et flow af operationer med få eller ingen dataafhængigheder.
Dette opnås med Zstandard ved at adskille data i flere parallelle strømme. En ny generation af Huffman-dekoder, Huff0, er i stand til at afkode flere symboler parallelt med en enkelt kerne. En sådan gevinst er kumulativ med multithreading, som anvender flere kerner.
Branchless design
Nye CPU’er er mere kraftfulde og når meget høje frekvenser, men dette er kun muligt takket være en flertrinstilgang, hvor en instruktion opdeles i en pipeline af flere trin. Ved hver clockcyklus er CPU’en i stand til at udstede resultatet af flere operationer, afhængigt af de tilgængelige ALU’er. Jo flere ALU’er der anvendes, jo mere arbejde udfører CPU’en, og jo hurtigere komprimering finder derfor sted. Det er afgørende for moderne CPU’ers ydeevne at holde ALU’erne fodret med arbejde.
Dette viser sig at være vanskeligt. Overvej følgende enkle situation:
if (condition) doSomething() else doSomethingElse()Når den støder på dette, ved CPU’en ikke, hvad den skal gøre, da den er afhængig af værdien af condition. En forsigtig CPU ville vente på resultatet af condition, før den arbejdede på en af de to grene, hvilket ville være ekstremt spildt.
De nuværende CPU’er gambler. De gør det på en intelligent måde takket være en branch predictor, som i alt væsentligt fortæller dem det mest sandsynlige resultat af evalueringen af condition. Når væddemålet er rigtigt, forbliver pipelinen fuld, og der udstedes løbende instruktioner. Når væddemålet er forkert (en fejlforudsigelse), skal CPU’en stoppe alle operationer, der er startet spekulativt, vende tilbage til afgreningen og tage den anden retning. Dette kaldes en pipeline flush, og det er ekstremt dyrt i moderne CPU’er.
For 25 år siden var pipeline flush et uproblematisk problem. I dag er det så vigtigt, at det er afgørende at designe formater, der er kompatible med forgreningsløse algoritmer. Lad os som eksempel se på en bit-stream-opdatering:
/* classic version */while (nbBitsUsed >= 8) { /* each while test is a branch */ accumulator <<= 8; accumulator += *byte++; nbBitsUsed -= 8;} /*>/* branch-less version */nbBytesUsed = nbBitsUsed >> 3;nbBitsUsed &= 7;ptr += nbBytesUsed;accumulator = read64(ptr);Som du kan se, har den grenløse version en forudsigelig arbejdsbyrde, uden nogen betingelse. CPU’en vil altid udføre det samme arbejde, og dette arbejde bliver aldrig smidt væk på grund af en fejlforudsigelse. I modsætning hertil udfører den klassiske version mindre arbejde, når (nbBitsUsed < 8). Men selve testen er ikke gratis, og hver gang testen gættes forkert, resulterer det i en fuld pipelineflush, hvilket koster mere end det arbejde, der udføres af den grenløse version.
Som du kan gætte, har denne bivirkning konsekvenser for den måde, data pakkes, læses og afkodes på. Zstandard er blevet skabt for at være venlig over for forgreningsløse algoritmer, især inden for kritiske loops.
Finite State Entropy: En næste generation af sandsynlighedskompressorer
I komprimering omdannes data først til et sæt symboler (modelleringsfasen), og derefter indkodes disse symboler ved hjælp af et minimum af bits. Dette andet trin kaldes entropitrinnet, til minde om Claude Shannon, som nøjagtigt beregner kompressionsgrænsen for et sæt symboler med givne sandsynligheder (kaldet “Shannon-grænsen”). Målet er at komme tæt på denne grænse og samtidig bruge så få CPU-ressourcer som muligt.
En meget almindelig algoritme er Huffman-kodning, der anvendes i Deflate. Den giver den bedst mulige præfikskode, idet det antages, at hvert symbol beskrives med et naturligt antal bits (1 bit, 2 bits …). Dette fungerer fint i praksis, men begrænsningen af naturlige tal betyder, at det er umuligt at opnå høje kompressionsforhold, fordi et symbol nødvendigvis bruger mindst 1 bit.
En bedre metode kaldes aritmetisk kodning, som kan komme vilkårligt tæt på Shannon-grænsen -log2(P), og som derfor bruger brøkdele af bits pr. symbol. Det udmønter sig i et bedre kompressionsforhold, når sandsynlighederne er høje, men det bruger også mere CPU-kraft. I praksis kæmper selv optimerede aritmetiske kodere med hastigheden, især på dekomprimeringssiden, som kræver divisioner med et forudsigeligt resultat (f.eks. ikke et flydende komma), og som viser sig at være langsomme.
Finite State Entropy er baseret på en ny teori kaldet ANS (Asymmetric Numeral System) af Jarek Duda. Finite State Entropy er en variant, der forudberegner mange kodningstrin i tabeller, hvilket resulterer i en entropi-kodec, der er lige så præcis som aritmetisk kodning, og som kun anvender additioner, tabelopslag og forskydninger, hvilket er omtrent samme kompleksitetsniveau som Huffman. Det reducerer også ventetiden for at få adgang til det næste symbol, da det er umiddelbart tilgængeligt fra tilstandsværdien, mens Huffman kræver en forudgående bitstream-afkodningsoperation. At forklare, hvordan den fungerer, ligger uden for rammerne af dette indlæg, men hvis du er interesseret, findes der en række artikler, der beskriver dens indre funktion.
Repcode-modellering
Repcode-modellering komprimerer effektivt strukturerede data, som indeholder sekvenser af næsten ækvivalent indhold, der kun adskiller sig med en eller få bytes. Denne metode er ikke ny, men blev først anvendt efter Deflates offentliggørelse, så den findes ikke i zlib/gzip.
Effektiviteten af repcode-modellering afhænger i høj grad af den type data, der komprimeres, og varierer fra en enkelt til en tocifret komprimeringsforbedring. Disse kombinerede forbedringer giver tilsammen en bedre og hurtigere komprimeringsoplevelse, der tilbydes inden for Zstandard-biblioteket.
Zstandard i praksis
Som tidligere nævnt er der flere typiske anvendelsestilfælde for komprimering. For at en algoritme kan være overbevisende, skal den enten være ekstraordinært god til ét specifikt anvendelsestilfælde, f.eks. komprimering af menneskeligt læsbar tekst, eller meget god til mange forskellige anvendelsestilfælde. Zstandard har valgt sidstnævnte fremgangsmåde. En måde at tænke på anvendelsestilfælde på er, hvor mange gange et bestemt stykke data kan blive dekomprimeret. Zstandard har fordele i alle disse tilfælde.
Mange gange. For data, der behandles mange gange, er dekomprimeringshastighed og muligheden for at vælge et meget højt komprimeringsforhold uden at gå på kompromis med dekomprimeringshastigheden fordelagtige. Lagringen af den sociale graf på Facebook bliver f.eks. læst gentagne gange, efterhånden som du og dine venner interagerer med webstedet. Uden for Facebook omfatter eksempler på, hvornår data skal dekomprimeres mange gange, filer, der downloades fra en server, f.eks. kildekoden til Linux-kernen eller de RPM’er, der installeres på servere, JavaScript og CSS, der anvendes af en webside, eller kørsel af tusindvis af MapReduces over data i et datawarehouse.
Men kun én gang. For data, der kun komprimeres én gang, især til transmission over et netværk, er komprimering et flygtigt øjeblik i datastrømmen. Det mindre overhead på serveren betyder, at serveren kan håndtere flere anmodninger pr. sekund. Mindre overhead på klienten betyder, at der kan handles hurtigere på dataene. Typisk opstår dette i forbindelse med klient/server-situationer, hvor dataene er unikke for klienten, f.eks. et webserversvar, der er tilpasset – f.eks. de data, der bruges til at gengive, når du modtager en besked fra en ven på Messenger. Nettoresultatet er, at din mobilenhed indlæser sider hurtigere, bruger mindre batteri og bruger mindre af dit dataabonnement. Især Zstandard passer meget bedre til mobilscenarierne end andre algoritmer på grund af den måde, hvorpå den håndterer små data.
Måske aldrig. Selv om det tilsyneladende er kontraintuitivt, er det ofte tilfældet, at et stykke data – f.eks. sikkerhedskopier eller logfiler – aldrig vil blive dekomprimeret, men kan læses, hvis det er nødvendigt. For denne type data skal komprimeringen typisk være hurtig, gøre dataene små (med en tids-/pladsafvejning, der passer til situationen) og måske gemme en kontrolsum, men ellers være usynlig. I de sjældne tilfælde, hvor der er behov for at dekomprimere data, må komprimeringen ikke forsinke den operationelle brugssituation. Hurtig dekomprimering er gavnlig, fordi det ofte er en lille del af dataene (f.eks. en specifik fil i sikkerhedskopien eller en besked i en logfil), der skal findes hurtigt.
I alle disse tilfælde giver Zstandard mulighed for at komprimere og dekomprimere mange gange hurtigere end gzip, og de resulterende komprimerede data er mindre.
Små data
Der er et andet anvendelsesområde for komprimering, som får mindre opmærksomhed, men som kan være ret vigtigt: små data. Der er tale om anvendelsesmønstre, hvor data produceres og forbruges i små mængder, f.eks. JSON-meddelelser mellem en webserver og en browser (typisk hundredvis af bytes) eller sider med data i en database (et par kilobyte).
Databaser udgør et interessant anvendelsestilfælde. Systemer som MySQL, PostgreSQL og MongoDB lagrer alle data, der er beregnet til realtidsadgang. De seneste hardwarefordele, især omkring udbredelsen af flash-enheder (SSD-enheder), har grundlæggende ændret balancen mellem størrelse og gennemløb – vi lever nu i en verden, hvor IOP’er (IO-operationer pr. sekund) er ret høje, men kapaciteten af vores lagerenheder er lavere, end den var, da harddiske herskede i datacentret.
Dertil kommer, at flash har en interessant egenskab med hensyn til skriveudholdenhed – efter tusindvis af skrivninger til den samme sektion af enheden kan denne sektion ikke længere acceptere skrivninger, hvilket ofte fører til, at enheden tages ud af drift. Derfor er det naturligt at søge efter måder at reducere mængden af data, der skrives på, fordi det kan betyde flere data pr. server og brænde enheden af i et langsommere tempo. Datakomprimering er en strategi til dette, og databaser er også ofte optimeret med henblik på ydeevne, hvilket betyder, at læse- og skriveydelse er lige vigtige.
Der er dog en komplikation ved brug af datakomprimering med databaser. Databaser kan lide at få tilfældig adgang til data, mens de fleste typiske anvendelsestilfælde for komprimering læser en hel fil i lineær rækkefølge. Dette er et problem, fordi datakomprimering i bund og grund fungerer ved at forudsige fremtiden på baggrund af fortiden – algoritmerne ser på dine data sekventielt og forudsiger, hvad de kan se i fremtiden. Jo mere præcise forudsigelserne er, jo mindre kan dataene gøres.
Når du komprimerer små data, f.eks. sider i en database eller små JSON-dokumenter, der sendes til din mobilenhed, er der simpelthen ikke meget “fortid” at bruge til at forudsige fremtiden. Komprimeringsalgoritmer har forsøgt at afhjælpe dette ved at bruge pre-shared dictionaries til effektivt at starte med en jump-start. Dette gøres ved på forhånd at dele et statisk sæt af “tidligere” data som et frø for komprimeringen.
Zstandard bygger på denne fremgangsmåde med stærkt optimerede algoritmer og API’er til ordbogskomprimering. Desuden indeholder Zstandard værktøj (zstd --train) til let at lave ordbøger til brugerdefinerede programmer og bestemmelser til registrering af standardordbøger med henblik på deling med større fællesskaber. Mens komprimeringen varierer afhængigt af datamaterialet, kan komprimering af små data være alt fra 2x til 5x bedre end komprimering uden ordbøger.
Dordbøger i aktion
Selv om det kan være svært at lege med en ordbog i forbindelse med en kørende database (det kræver trods alt betydelige ændringer af databasen), kan du se ordbøger i aktion med andre typer små data. JSON, lingua franca for små data i den moderne verden, har tendens til at være små, repetitive poster. Der er utallige offentlige datasæt til rådighed; i forbindelse med denne demonstration vil vi bruge datasættet “user” fra GitHub, der er tilgængeligt via HTTP. Her er en prøvepost fra dette datasæt:
{ "login": "octocat", "id": 1, "avatar_url": "https://github.com/images/error/octocat_happy.gif", "gravatar_id": "", "url": "https://api.github.com/users/octocat", "html_url": "https://github.com/octocat", "followers_url": "https://api.github.com/users/octocat/followers", "following_url": "https://api.github.com/users/octocat/following{/other_user}", "gists_url": "https://api.github.com/users/octocat/gists{/gist_id}", "starred_url": "https://api.github.com/users/octocat/starred{/owner}{/repo}", "subscriptions_url": "https://api.github.com/users/octocat/subscriptions", "organizations_url": "https://api.github.com/users/octocat/orgs", "repos_url": "https://api.github.com/users/octocat/repos", "events_url": "https://api.github.com/users/octocat/events{/privacy}", "received_events_url": "https://api.github.com/users/octocat/received_events", "type": "User", "site_admin": false }Som du kan se, er der en hel del gentagelser her – vi kan komprimere disse pænt! Men hver bruger er lidt under 1 KB, og de fleste komprimeringsalgoritmer har virkelig brug for flere data for at strække deres ben. Et sæt på 1.000 brugere tager ca. 850 KB at lagre ukomprimeret. Hvis man naivt anvender enten gzip eller zstd individuelt på hver enkelt fil, reduceres dette til lidt over 300 KB; ikke dårligt! Men hvis vi opretter en engangsordbog med zstd, falder størrelsen til 122 KB – hvilket bringer det oprindelige kompressionsforhold fra 2,8x til 6,9. Dette er en betydelig forbedring, der er tilgængelig out-of-box med zstd:
$ zstd --train -o ../json.zdict -r .sorting 982 files of total size 0 MB ...finding patterns ...statistics ...Save dictionary of size 65599 into file ../json.zdict$ du -h --apparent-size .846K .$ zstd --rm -D ../json.zdict -r .$ du -h --apparent-size .122K .Valg af komprimeringsniveau
Som det fremgår ovenfor, tilbyder Zstandard et betydeligt antal niveauer. Denne tilpasning er kraftfuld, men fører til svære valg. Den bedste måde at beslutte sig på er at gennemgå dine data og måle og beslutte, hvilke kompromiser du ønsker at foretage. Hos Facebook finder vi standardniveau 3 passende til mange anvendelsestilfælde, men fra tid til anden justerer vi dette en smule afhængigt af, hvad vores flaskehals er (ofte forsøger vi at mætte en netværksforbindelse eller en diskspindel); andre gange bekymrer vi os mere om den lagrede størrelse og bruger et højere niveau.
For at få de resultater, der er mest skræddersyet til dine behov, skal du i sidste ende overveje både den hardware, du bruger, og de data, du bekymrer dig om – der er ingen faste forskrifter, der kan gives uden kontekst. Når du er i tvivl, skal du dog enten holde dig til standardniveauet 3 eller noget fra 6 til 9 for at få en god afvejning af hastighed i forhold til plads; gem niveau 20+ til de tilfælde, hvor du virkelig kun bekymrer dig om størrelsen og ikke om komprimeringshastigheden.
Afprøv det
Zstandard er både et kommandolinjeværktøj (zstd) og et bibliotek. Det er skrevet i meget bærbar C, hvilket gør det egnet til praktisk talt alle platforme, der anvendes i dag – uanset om det er de servere, der driver din virksomhed, din bærbare computer eller endda telefonen i din lomme. Du kan hente den fra vores github-repository, kompilere den med en simpel make install og begynde at bruge den, som du ville bruge gzip:
$ zstd access.logaccess.log : 8.07% (6695078 => 540336 bytes, access.log.zst)Som du måske forventer, kan du bruge den som en del af en kommandopipeline, f.eks. til at sikkerhedskopiere din kritiske MySQL-database:
$ mysqldump --single-transaction --opt pokemon | zstd -q -o /srv/backups/mysqldump.sql.zstKommandoen tar understøtter forskellige komprimeringsimplementeringer out-of-box, så når du installerer Zstandard, kan du straks arbejde med tarballs komprimeret med Zstandard. Her er et simpelt eksempel, der viser den i brug med tar og hastighedsforskellen sammenlignet med gzip:
$ time tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4tar -I zstd -cf linux-4.6.4.tar.zst linux-4.6.4 3.15s user 0.50s system 107% cpu 3.396 total$ time tar -zcf linux-4.6.4.tar.gz linux-4.6.4tar -zcf linux-4.6.4.tar.gz linux-4.6.4 13.74s user 0.43s system 102% cpu 13.784 totalBortset fra kommandolinjen er der API’erne, som er dokumenteret i headerfilerne i repositoriet (start her for at få en oversigt over API’erne). Vi inkluderer også et zlib-kompatibelt wrapper-API (libWrapper) for nemmere integration med værktøjer, der allerede har zlib-grænseflader. Endelig inkluderer vi en række eksempler, både på grundlæggende brug og på mere avanceret brug som f.eks. ordbøger og streaming, også i GitHub-repositoriet.
Der kommer mere
Mens vi har ramt 1.0 og anser Zstandard for klar til enhver form for produktionsbrug, er vi ikke færdige. Kommer i fremtidige versioner:
- Multi-threaded kommandolinjekomprimering for endnu hurtigere gennemløb på store datasæt, svarende til pigz-værktøjet til zlib.
- Nye komprimeringsniveauer, i begge retninger, hvilket giver mulighed for endnu hurtigere komprimering og højere kompressionsforhold.
- Et af fællesskabet vedligeholdt foruddefineret sæt af kompressionsordbøger for almindelige datasæt såsom JSON, HTML og almindelige netværksprotokoller.
Vi vil gerne takke alle bidragydere, både af kode og feedback, som hjalp os med at nå frem til 1.0. Dette er kun begyndelsen. Vi ved, at for at Zstandard kan leve op til sit potentiale, har vi brug for din hjælp. Som nævnt ovenfor kan du prøve Zstandard i dag ved at hente kildekoden eller færdigbyggede binære filer fra vores GitHub-projekt, eller, for Mac-brugere, ved at installere via homebrew (brew install zstd). Vi vil meget gerne have feedback og interessante anvendelsestilfælde, som du har, samt yderligere sprogbindinger og hjælp til at integrere det med dine foretrukne open source-projekter.
Fodnoter
- Mens tabsfri datakomprimering er fokus for dette indlæg, findes der et beslægtet, men meget forskelligt område for tabsgivende datakomprimering, der primært bruges til billeder, lyd og video.
- Deflate, zlib, gzip – tre navne, der er flettet sammen. Deflate er den algoritme, der anvendes af zlib- og gzip-implementeringerne. Zlib er et bibliotek, der leverer Deflate, og gzip er et kommandolinjeværktøj, der bruger zlib til deflatering af data samt checksumming. Denne checksumming kan have et betydeligt overhead.
- Alle benchmarks blev udført på en Intel E5-2678 v3, der kører ved 2,5 GHz på en Centos 7-maskine. Kommandolinjeværktøjer (
zstdoggzip) blev bygget med systemet GCC, 4.8.5. Algoritme-benchmarks udført af lzbench blev bygget med GCC 6.
Skriv et svar