I dette indlæg vil vi se nærmere på de mest udbredte maskinlæringsalgoritmer. Der findes et stort udvalg af dem, og det er let at føle sig forvirret, når man hører udtryk som “instansbaserede læringsalgoritmer” og “perceptron”.
Sædvanligvis inddeles alle maskinlæringsalgoritmer i grupper baseret på enten deres læringsstil, funktion eller de problemer, de løser. I dette indlæg finder du en klassificering baseret på læringsstil. Jeg vil også nævne de almindelige opgaver, som disse algoritmer hjælper med at løse.
Antallet af maskinlæringsalgoritmer, der bruges i dag, er stort, og jeg vil ikke nævne 100 % af dem. Jeg vil dog gerne give et overblik over de mest almindeligt anvendte.
- Supervised learning algorithms
- Klassifikationsalgoritmer
- Naive Bayes
- Multinomial Naive Bayes
- Logistisk regression
- Beslutningstræer
- SVM (Support Vector Machine)
- Regressionsalgoritmer
- Linær regression
- Uovervågede læringsalgoritmer
- Clustering
- K-means clustering
- K-nearest neighbor
- Dimensionalitetsreduktion
- Associeringsregelindlæring
- Reinforcement learning
- Q-Learning
- Ensemble learning
- Bagging
- Boosting
- Randomskov
- Stacking
- Neurale netværk
- Konklusion
Supervised learning algorithms

Hvis du ikke er bekendt med begreber som “supervised learning” og “unsupervised learning”, kan du læse vores indlæg om AI vs. ML, hvor dette emne er dækket i detaljer. Lad os nu blive bekendt med algoritmerne.
Klassifikationsalgoritmer
Naive Bayes

Bayesianske algoritmer er en familie af probabilistiske klassifikatorer, der anvendes i ML, baseret på anvendelse af Bayes’ teorem.
Naive Bayes-klassifikator var en af de første algoritmer, der blev anvendt til maskinlæring. Den er velegnet til binær og multiklasseklassifikation og gør det muligt at foretage forudsigelser og prognoser af data baseret på historiske resultater. Et klassisk eksempel er spamfiltreringssystemer, der anvendte Naive Bayes frem til 2010 og viste tilfredsstillende resultater. Men da Bayes’ gift blev opfundet, begyndte programmører at tænke på andre måder at filtrere data på.
Med Bayes’ teorem er det muligt at fortælle, hvordan forekomsten af en begivenhed påvirker sandsynligheden for en anden begivenhed.
For eksempel beregner denne algoritme sandsynligheden for, at en bestemt e-mail er eller ikke er spam på baggrund af de typiske ord, der anvendes. Almindelige spam-ord er “tilbud”, “bestil nu” eller “ekstra indkomst”. Hvis algoritmen registrerer disse ord, er der en stor sandsynlighed for, at e-mailen er spam.
Naive Bayes antager, at funktionerne er uafhængige. Derfor kaldes algoritmen naiv.
Multinomial Naive Bayes
Ud over Naive Bayes klassifikator er der andre algoritmer i denne gruppe. For eksempel Multinomial Naive Bayes, som normalt anvendes til dokumentklassificering baseret på hyppigheden af visse ord i dokumentet.
Bayesianske algoritmer anvendes stadig til kategorisering af tekster og til detektion af svig. De kan også anvendes til maskinsyn (f.eks. ansigtsdetektion), markedssegmentering og bioinformatik.
Logistisk regression
Selv om navnet kan virke kontraintuitivt, er logistisk regression faktisk en type klassificeringsalgoritme.
Logistisk regression er en model, der foretager forudsigelser ved hjælp af en logistisk funktion for at finde afhængigheden mellem output- og inputvariablerne. Statquest har lavet en god video, hvor de forklarer forskellen mellem lineær og logistisk regression ved at tage som eksempel overvægtige mus.
Beslutningstræer
Et beslutningstræ er en simpel måde at visualisere en beslutningsmodel i form af et træ. Fordelene ved beslutningstræer er, at de er lette at forstå, fortolke og visualisere. Desuden kræver de kun en lille indsats for datapræparation.
Men de har også en stor ulempe. Træerne kan være ustabile på grund af selv de mindste variationer (varians) i data. Det er også muligt at skabe overkomplekse træer, som ikke generaliserer godt. Dette kaldes overfitting. Bagging, boosting og regularization hjælper til at bekæmpe dette problem. Vi kommer til at tale om dem senere i indlægget.
Elementerne i ethvert beslutningstræ er:
- Rødknude, der stiller det vigtigste spørgsmål. Den har pilene, der peger nedad fra den, men ingen pile, der peger til den. Forestil dig for eksempel, at du opbygger et træ til at beslutte, hvilken slags pasta du skal have til aftensmad.
- Afgreninger. En underafdeling af et træ kaldes en gren eller nogle gange et undertræ.
- Beslutningsknuder. Det er underknuder til rodknuden, som også kan opdeles i flere knuder. Dine beslutningsnoder kan være “carbonara?” eller “med svampe?”.
- Lave eller terminalknuder. Disse knuder deler sig ikke. De repræsenterer endelige beslutninger eller forudsigelser.
Det er også vigtigt at nævne opsplitning. Dette er processen med at opdele en knude i underknuder. Hvis du f.eks. ikke er vegetar, er carbonara okay, hvis du ikke er vegetar. Men hvis du er det, skal du spise pasta med svampe. Der er også en proces med fjernelse af knuder, der kaldes beskæring.
Decision tree-algoritmer betegnes CART (Classification and Regression Trees). Beslutningstræer kan arbejde med kategoriske eller numeriske data.
- Regressionstræer anvendes, når variablerne har numerisk værdi.
- Klassifikationstræer kan anvendes, når dataene er kategoriske (klasser).
Beslutningstræer er ret intuitive at forstå og bruge. Derfor er trædiagrammer almindeligt anvendt i en lang række brancher og discipliner. GreyAtom giver en bred oversigt over forskellige typer beslutningstræer og deres praktiske anvendelser.
SVM (Support Vector Machine)
Support vector machines er en anden gruppe af algoritmer, der anvendes til klassifikations- og undertiden regressionsopgaver. SVM er fantastisk, fordi den giver ret præcise resultater med minimal beregningskraft.
Målet med SVM er at finde en hyperplan i et N-dimensionelt rum (hvor N svarer til antallet af funktioner), der tydeligt klassificerer datapunkterne. Resultaternes nøjagtighed hænger direkte sammen med den hyperplan, som vi vælger. Vi skal finde et plan, der har den største afstand mellem datapunkterne i begge klasser.
Denne hyperplan er grafisk repræsenteret som en linje, der adskiller den ene klasse fra den anden. Datapunkter, der falder på forskellige sider af hyperplanet, henføres til forskellige klasser.
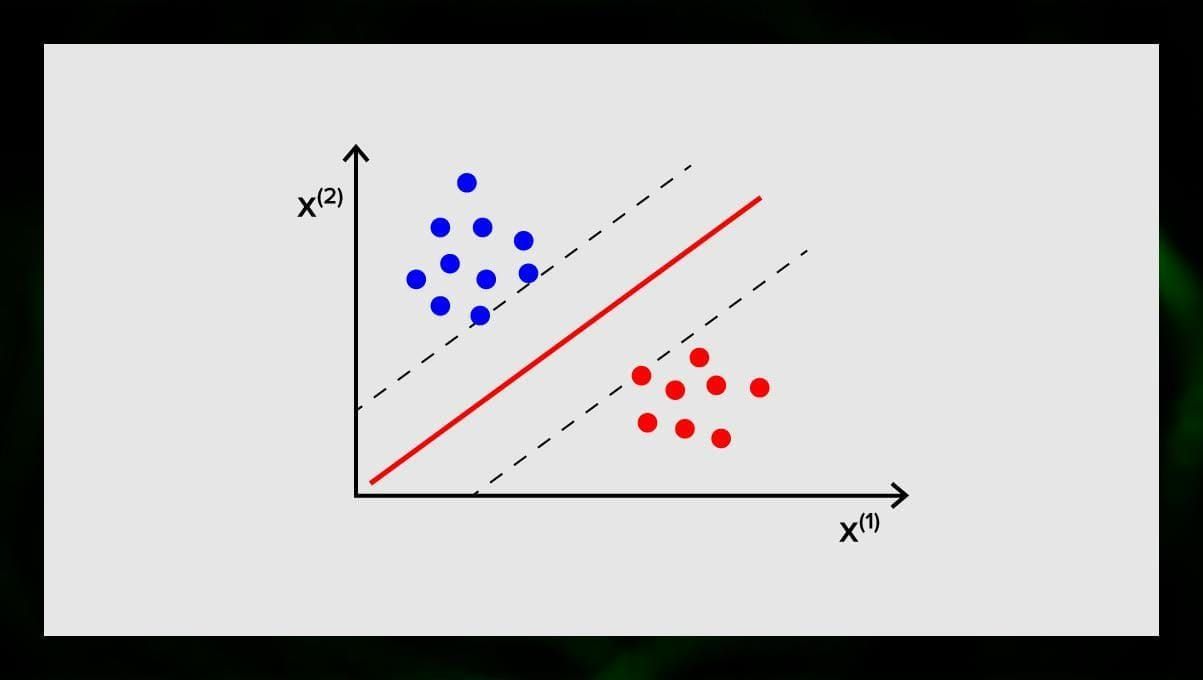
Bemærk, at hyperplanets dimension afhænger af antallet af funktioner. Hvis antallet af inputfunktioner er 2, er hyperplanet blot en linje. Hvis antallet af inputfunktioner er 3, bliver hyperplanet et todimensionalt plan. Det bliver vanskeligt at tegne en model på en graf, når antallet af funktioner overstiger 3. Så i dette tilfælde vil du bruge Kernel-typer til at omdanne den til et 3-dimensionelt rum.
Hvorfor kaldes dette en Support Vector Machine? Støttevektorer er datapunkter, der ligger tættest på hyperplanet. De har direkte indflydelse på hyperplanets position og orientering og giver os mulighed for at maksimere klassifikatorens margin. Hvis støttevektorerne slettes, vil hyperplanets position ændres. Det er disse punkter, der hjælper os med at opbygge vores SVM.
SVM anvendes nu aktivt inden for medicinsk diagnose til at finde anomalier, i systemer til kontrol af luftkvalitet, til finansiel analyse og forudsigelser på aktiemarkedet og til maskinfejlkontrol i industrien.
Regressionsalgoritmer
Regressionsalgoritmer er nyttige inden for analytik, f.eks. når man forsøger at forudsige omkostningerne til værdipapirer eller salget af et bestemt produkt på et bestemt tidspunkt.
Linær regression
Linær regression forsøger at modellere forholdet mellem variabler ved at tilpasse en lineær ligning til de observerede data.
Der er forklarende og afhængige variabler. Afhængige variabler er ting, som vi ønsker at forklare eller forudsige. De forklarende forklarer, som det følger af navnet, forklarer noget. Hvis du ønsker at opbygge en lineær regression, antager du, at der er en lineær sammenhæng mellem dine afhængige og uafhængige variabler. Der er f.eks. en sammenhæng mellem kvadratmeterne på et hus og dets pris eller befolkningstætheden og kebabstederne i området.
Når du har foretaget denne antagelse, skal du som det næste finde ud af den specifikke lineære sammenhæng. Du skal finde en lineær regressionsligning for et datasæt. Det sidste trin er at beregne residualet.
Bemærk: Når regressionen tegner en lige linje, kaldes den lineær, når den er en kurve – polynomial.
Uovervågede læringsalgoritmer

Nu skal vi tale om algoritmer, der er i stand til at finde skjulte mønstre i umærkede data.
Clustering
Clustering betyder, at vi inddeler input i grupper efter graden af deres lighed med hinanden. Clustering er normalt et af trinene i opbygningen af en mere kompleks algoritme. Det er mere enkelt at undersøge hver gruppe for sig og opbygge en model baseret på deres egenskaber i stedet for at arbejde med det hele på én gang. Den samme teknik bruges konstant i marketing og salg til at opdele alle potentielle kunder i grupper.
Meget almindelige clustering-algoritmer er k-means clustering og k-nearest neighbor.
K-means clustering
K-means clustering opdeler mængden af elementer i vektorrummet i et foruddefineret antal klynger k. Et forkert antal klynger vil dog ugyldiggøre hele processen, så det er vigtigt at prøve det med varierende antal klynger. Hovedidéen i k-means-algoritmen er, at dataene opdeles tilfældigt i klynger, og herefter genberegnes centrum for hver klynge, der er opnået i det foregående trin, iterativt. Derefter opdeles vektorerne igen i klynger. Algoritmen stopper, når der på et tidspunkt ikke er nogen ændring i klyngerne efter en iteration.
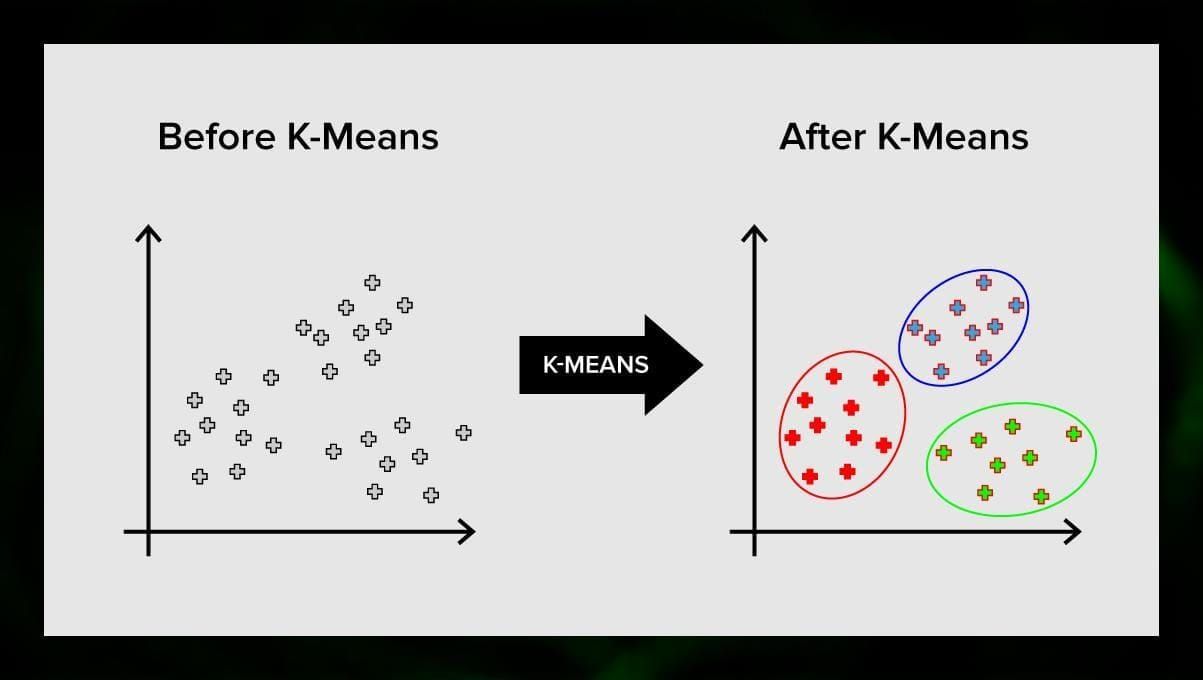
Denne metode kan anvendes til at løse problemer, når klyngerne er tydelige eller let kan adskilles fra hinanden uden overlapning af data.
K-nearest neighbor
kNN står for k-nearest neighbor. Dette er en af de enkleste klassifikationsalgoritmer, der nogle gange anvendes i regressionsopgaver.
For at træne klassifikatoren skal du have et sæt data med foruddefinerede klasser. Markeringen foretages manuelt med inddragelse af specialister inden for det undersøgte område. Ved hjælp af denne algoritme er det muligt at arbejde med flere klasser eller opklare situationer, hvor input hører til mere end én klasse.
Metoden er baseret på den antagelse, at lignende etiketter svarer til nærliggende objekter i attributvektorrummet.
Moderne softwaresystemer bruger kNN til visuel mønstergenkendelse, f.eks. til at scanne og opdage skjulte pakker nederst i kurven ved kassen (f.eks. AmazonGo). K-nearest neighbor bruges også i bankverdenen til at opdage mønstre i brugen af kreditkort. kNN-algoritmer analyserer alle data og opdager usædvanlige mønstre, der indikerer mistænkelig aktivitet.
Dimensionalitetsreduktion
Principal component analysis (PCA) er en vigtig teknik at forstå for effektivt at kunne løse ML-relaterede problemer.
Forestil dig, at du har en masse variabler at tage hensyn til. Du skal f.eks. gruppere byer i tre grupper: gode til at bo, dårlige til at bo og så-så-så. Hvor mange variabler skal du tage hensyn til? Sandsynligvis en hel del. Forstår du sammenhængen mellem dem? Ikke rigtig. Så hvordan kan du tage alle de variabler, du har indsamlet, og fokusere på kun nogle få af dem, som er de vigtigste?
I tekniske termer ønsker du at “reducere dimensionen af dit feature space”. Ved at reducere dimensionen af dit feature space lykkes det dig at få færre relationer mellem variabler at tage hensyn til, og du er mindre tilbøjelig til at overpasse din model.
Der er mange måder at opnå dimensionalitetsreduktion på, men de fleste af disse teknikker falder i en af to klasser:
- Feature Elimination;
- Feature Extraction.
Feature Elimination betyder, at du reducerer antallet af features ved at eliminere nogle af dem. Fordelene ved denne metode er, at den er enkel og bevarer fortolkeligheden af dine variabler. Som en ulempe er det dog, at du får nul information fra de variabler, du har besluttet at fjerne.
Feature ekstraktion undgår dette problem. Målet, når man anvender denne metode, er at udtrække et sæt funktioner fra det givne datasæt. Featureudtrækning har til formål at reducere antallet af features i et datasæt ved at skabe nye features baseret på de eksisterende features (og derefter kassere de oprindelige features). Det nye reducerede sæt af features skal oprettes på en sådan måde, at det er i stand til at opsummere de fleste af de oplysninger, der er indeholdt i det oprindelige sæt af features.
Principal component analysis er en algoritme til feature extraction. den kombinerer inputvariablerne på en bestemt måde, og derefter er det muligt at droppe de “mindst vigtige” variabler, mens man stadig beholder de mest værdifulde dele af alle variablerne.
En af de mulige anvendelser af PCA er, når billederne i datasættet er for store. En reduceret feature-repræsentation hjælper til hurtigt at håndtere opgaver som f.eks. billedmatching og retrieval.
Associeringsregelindlæring
Apriori er en af de mest populære algoritmer til søgning efter associeringsregler. Den er i stand til at behandle store datamængder på relativt kort tid.
Det er sådan, at databaserne i mange projekter i dag er meget store og når op på gigabyte og terabyte. Og de vil fortsætte med at vokse. Derfor har man brug for en effektiv, skalerbar algoritme til at finde associative regler på kort tid. Apriori er en af disse algoritmer.
For at kunne anvende algoritmen er det nødvendigt at forberede dataene ved at konvertere dem alle til den binære form og ændre deres datastruktur.
Sædvanligvis anvender man denne algoritme på en database, der indeholder et stort antal transaktioner, f.eks. på en database, der indeholder oplysninger om alle de varer, som kunderne har købt i et supermarked.
Reinforcement learning

Reinforcement learning er en af de metoder inden for machine learning, der er med til at lære maskinen, hvordan den skal interagere med et bestemt miljø. I dette tilfælde fungerer omgivelserne (f.eks. i et videospil) som lærer. Det giver feedback til de beslutninger, som computeren træffer. På baggrund af denne belønning lærer maskinen at vælge den bedste fremgangsmåde. Det minder om den måde, børn lærer at undgå at røre ved en varm stegepande – ved at prøve og føle smerte.
Hvis man nedbryder denne proces, omfatter den disse enkle trin:
- Computeren observerer omgivelserne;
- Vælger en eller anden strategi;
- Handler i overensstemmelse med denne strategi;
- Erhverv enten en belønning eller en straf;
- Lærer af denne erfaring og forfiner strategien;
- Opnatter, indtil den optimale strategi er fundet.
Q-Learning
Der findes et par algoritmer, der kan bruges til Reinforcement Learning. En af de mest almindelige er Q-learning.
Q-learning er en modelfri forstærkningslæringsalgoritme. Q-learning er baseret på den belønning, der modtages fra omgivelserne. Agenten danner en nyttefunktion Q, som efterfølgende giver den mulighed for at vælge en adfærdsstrategi og tage hensyn til erfaringerne fra tidligere interaktioner med miljøet.
En af fordelene ved Q-læring er, at den er i stand til at sammenligne den forventede nytteværdi af de tilgængelige handlinger uden at danne miljømodeller.
Ensemble learning

Ensemble learning er en metode til løsning af et problem ved at opbygge flere ML-modeller og kombinere dem. Ensembleindlæring anvendes primært til at forbedre præstationen af klassifikations-, forudsigelses- og funktionsapproximationsmodeller. Andre anvendelser af ensembleindlæring omfatter kontrol af den beslutning, som modellen har truffet, udvælgelse af optimale funktioner til opbygning af modeller, inkrementel indlæring og ikke-stationær indlæring.
Nedenfor er nogle af de mere almindelige ensembleindlæringsalgoritmer.
Bagging
Bagging står for bootstrap-aggregering. Det er en af de tidligste ensemble-algoritmer med en overraskende god ydeevne. For at garantere diversiteten af klassifikatorer bruger man bootstrapede kopier af træningsdataene. Det betyder, at forskellige delmængder af træningsdata trækkes tilfældigt – med udskiftning – fra træningsdatasættet. Hver delmængde af træningsdata bruges til at træne en anden klassifikator af samme type. Derefter kan de enkelte klassifikatorer kombineres. For at gøre dette skal man tage en simpel flertalsafstemning af deres beslutninger. Den klasse, der blev tildelt af flertallet af klassifikatorer, er ensemblebeslutningen.
Boosting
Denne gruppe af ensemblealgoritmer svarer til bagging. Boosting anvender også en række klassifikatorer til at genudtage dataene og vælger derefter den optimale version ved flertalsafstemning. Ved boosting træner man iterativt svage klassifikatorer for at samle dem til en stærk klassifikator. Når klassifikatorerne tilføjes, tilskrives de normalt i nogle vægte, som beskriver nøjagtigheden af deres forudsigelser. Når en svag klassifikator er blevet tilføjet til ensemblet, genberegnes vægtene. Ukorrekt klassificerede indgange får mere vægt, og korrekt klassificerede instanser mister vægt. Således fokuserer systemet mere på eksempler, hvor der blev opnået en fejlagtig klassificering.
Randomskov
Randomskove eller tilfældige beslutningsskove er en ensembleindlæringsmetode til klassificering, regression og andre opgaver. For at opbygge en tilfældig skov skal du træne et væld af beslutningstræer på tilfældige prøver af træningsdata. Output af den tilfældige skov er det mest hyppige resultat blandt de enkelte træer. Tilfældige beslutningsskove bekæmper med succes overtilpasning på grund af algoritmens _tilfældige _natur.
Stacking
Stacking er en ensembleindlæringsteknik, der kombinerer flere klassifikations- eller regressionsmodeller via en meta-klassifikator eller en meta-regressor. Modellerne på basisniveau trænes på grundlag af et komplet træningssæt, hvorefter metamodellen trænes på output fra modellerne på basisniveau som funktioner.
Neurale netværk
Et neuralt netværk er en sekvens af neuroner forbundet med synapser, hvilket minder om strukturen i den menneskelige hjerne. Den menneskelige hjerne er dog endnu mere kompleks.
Det fantastiske ved neurale netværk er, at de kan bruges til stort set alle opgaver, lige fra spamfiltrering til computervision. De anvendes dog normalt til maskinoversættelse, anomalidetektion og risikostyring, talegenkendelse og sproggenerering, ansigtsgenkendelse og meget mere.
Et neuralt netværk består af neuroner, eller knuder. Hver af disse neuroner modtager data, behandler dem og overfører dem derefter til en anden neuron.
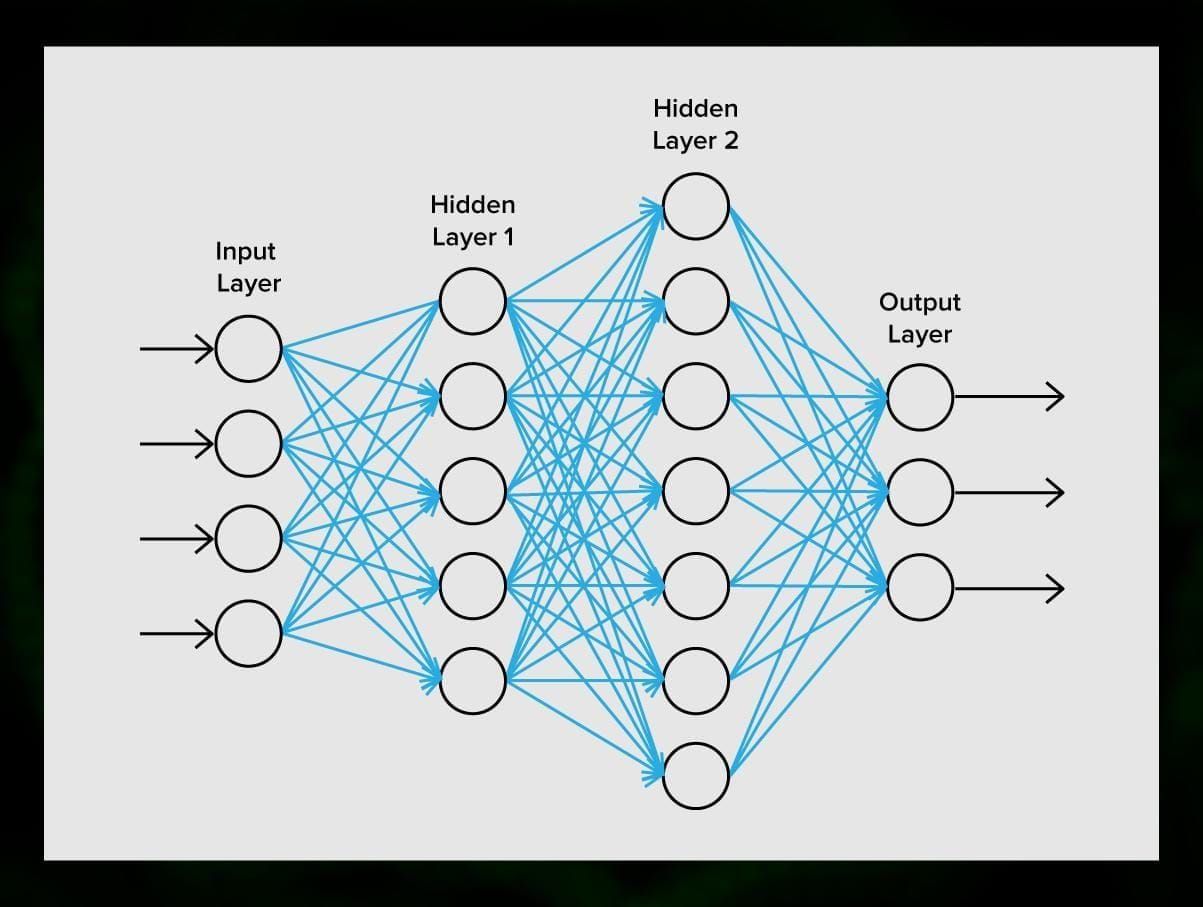
Alle neuroner behandler signalerne på samme måde. Men hvordan får vi så et forskelligt resultat? Det er synapserne, der forbinder neuroner med hinanden, der er ansvarlige for dette. Hver neuron kan have mange synapser, der dæmper eller forstærker signalet. Desuden er neuroner i stand til at ændre deres egenskaber over tid. Ved at vælge de korrekte synapseparametre vil vi kunne få de korrekte resultater af den indgående informationsomdannelse ved udgangen.
Der findes mange forskellige typer af NN:
- Feedforward neural networks (FF eller FFNN) og perceptrons § er meget ligetil, der er ingen sløjfer eller cyklusser i netværket. I praksis anvendes sådanne netværk sjældent, men de kombineres ofte med andre typer for at opnå nye.
- Et Hopfield-netværk (HN) er et fuldt forbundet neuralt netværk med en symmetrisk matrix af forbindelser. Et sådant netværk kaldes ofte et associativt hukommelsesnetværk. Ligesom en person, der ved at se den ene halvdel af bordet, kan forestille sig den anden halvdel, kan dette netværk, når det modtager et støjende bord, genskabe det fuldt ud.
- Det er meget forskelligt fra andre typer netværk, når det modtager et støjende bord.
- Det er et konvolutionelt neuronalt netværk (CNN) og et dybt konvolutionelt neuronalt netværk (DCNN). De anvendes normalt til billedbehandling, lyd- eller videorelaterede opgaver. En typisk måde at anvende CNN på er at klassificere billeder.
Mange forskellige typer af neurale netværk er interessante at observere. Det er muligt at gøre det i NN zoo.
Konklusion
Dette indlæg er en bred oversigt over forskellige ML-algoritmer, men der er stadig meget at sige. Hold dig opdateret på vores Twitter, Facebook og Medium for flere vejledninger og indlæg om de spændende muligheder, som maskinlæring giver.
Skriv et svar