Det er vigtigt at have overblik over din Java-applikation for at forstå, hvordan den fungerer lige nu, hvordan den fungerede engang i fortiden, og øge din forståelse af, hvordan den kan fungere i fremtiden. Oftest er analyse af logfiler den hurtigste måde at opdage, hvad der gik galt, hvilket gør logning i Java afgørende for at sikre din applikations ydeevne og sundhed samt minimere og reducere eventuel nedetid. At have en centraliseret lognings- og overvågningsløsning hjælper med at reducere Mean Time To Repair ved at forbedre effektiviteten af dit Ops- eller DevOps-team.
Gennem at følge god praksis får du mere værdi ud af dine logs og gør det lettere at bruge dem. Du vil lettere kunne lokalisere den grundlæggende årsag til fejl og dårlig ydeevne og løse problemerne, før de påvirker slutbrugerne. Så i dag vil jeg gerne dele nogle af de bedste praksisser, som du bør sværge til, når du arbejder med Java-applikationer. Lad os gå i dybden.
- Brug et standardlogbibliotek
- Vælg dine appenders med omtanke
- Brug meningsfulde meddelelser
- Logning af Java Stack Traces
- Logging Java Exceptions
- Brug passende logniveau
- Log i JSON
- Hold logstrukturen konsistent
- Føj kontekst til dine logs
- Java Logging in Containers
- Log ikke for meget eller for lidt
- Hold publikum i tankerne
- Undergå logning af følsomme oplysninger
- Brug en loghåndteringsløsning til at centralisere & Overvåg Java-logs
- Konklusion
- Aktie
Brug et standardlogbibliotek
Logning i Java kan gøres på et par forskellige måder. Du kan bruge et dedikeret logningsbibliotek, et fælles API eller endda bare skrive logs til en fil eller direkte til et dedikeret logningssystem. Når du vælger logningsbibliotek til dit system, skal du dog tænke dig godt om. Ting du skal overveje og evaluere er ydeevne, fleksibilitet, appenders til nye logcentraliseringsløsninger osv. Hvis du binder dig direkte til et enkelt framework kan skiftet til et nyere bibliotek kræve en betydelig mængde arbejde og tid. Husk det, og gå efter det API, der giver dig fleksibilitet til at skifte logbibliotek i fremtiden. Ligesom ved skiftet fra Log4j til Logback og til Log4j 2 er det eneste, du skal gøre, når du bruger SLF4J API’et, at ændre afhængigheden, ikke koden.
Hvis du er nybegynder inden for Java-logbiblioteker, kan du læse vores begyndervejledninger:
- Log4j Tutorial
- Logback Tutorial
- Log4j2 Tutorial
- SLF4J Tutorial
Vælg dine appenders med omtanke
Appenders definerer, hvor dine logbegivenheder skal leveres. De mest almindelige appenders er Console- og File Appenders. Selv om de er nyttige og almindeligt kendte, opfylder de måske ikke dine krav. Det kan f.eks. være, at du ønsker at skrive dine logfiler på en asynkron måde, eller at du ønsker at sende dine logfiler over netværket ved hjælp af appendere som den til Syslog, som her:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Husk dog, at brugen af appendere som den ovenfor viste gør din logføringspipeline modtagelig over for netværksfejl og kommunikationsforstyrrelser. Det kan resultere i, at logfiler ikke bliver sendt til deres destination, hvilket måske ikke er acceptabelt. Du vil også gerne undgå, at logning påvirker dit system, hvis appenderen er designet på en blokerende måde. Hvis du vil vide mere, kan du læse mere i vores blogindlæg Logging libraries vs Log shippers.
Brug meningsfulde meddelelser
En af de afgørende ting, når det kommer til at oprette logs, men alligevel en af de ikke så nemme, er at bruge meningsfulde meddelelser. Dine logbegivenheder bør indeholde meddelelser, der er unikke for den givne situation, som klart beskriver dem og informerer den person, der læser dem. Forestil dig, at der er opstået en kommunikationsfejl i din applikation. Du kunne gøre det sådan her:
LOGGER.warn("Communication error");
Men du kunne også oprette en besked som denne:
LOGGER.warn("Error while sending documents to events Elasticsearch server, response code %d, response message %s. The message sending will be retried.", responseCode, responseMessage);
Du kan nemt se, at den første besked vil informere den person, der kigger på logfilerne, om nogle kommunikationsproblemer. Denne person vil sandsynligvis få konteksten, navnet på loggeren og linjenummeret, hvor advarslen skete, men det er alt. For at få mere kontekst skal den pågældende person se på koden, vide hvilken version af koden fejlen vedrører osv. Dette er ikke sjovt og ofte ikke let, og bestemt ikke noget man ønsker at gøre, mens man forsøger at fejlfinde et produktionsproblem så hurtigt som muligt.
Den anden besked er bedre. Den giver nøjagtige oplysninger om, hvilken type kommunikationsfejl der er sket, hvad programmet gjorde på det tidspunkt, hvilken fejlkode det fik, og hvad svaret fra fjernserveren var. Endelig informerer den også om, at afsendelsen af meddelelsen vil blive forsøgt igen. Det er helt klart nemmere og mere behageligt at arbejde med sådanne meddelelser.
Til sidst skal du tænke på meddelelsens størrelse og verbositet. Lad være med at logge oplysninger, der er for mundrette. Disse data skal gemmes et sted for at være nyttige. Én meget lang meddelelse vil ikke være et problem, men hvis denne linje gentages hundredvis af gange i løbet af et minut, og du har mange mundrette logfiler, kan det være problematisk at opbevare sådanne data i længere tid, og i sidste ende vil det også koste mere.
Logning af Java Stack Traces
En af de meget vigtige dele af Java-logning er Java Stack Traces. Tag et kig på følgende kode:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JExceptionNoThrowable { private static final Logger LOGGER = LogManager.getLogger(Log4JExceptionNoThrowable.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread"); } }}
Overstående kode vil resultere i, at en undtagelse bliver kastet, og en logmeddelelse, der vil blive udskrevet til konsollen med vores standardkonfiguration, vil se ud som følger:
11:42:18.952 ERROR - Error while executing main thread
Som du kan se, er der ikke mange oplysninger der. Vi ved kun, at problemet er opstået, men vi ved ikke, hvor det er sket, eller hvad problemet var osv. Ikke særlig informativt.
Se nu på den samme kode med en lidt ændret logningsanvisning:
package com.sematext.blog.logging;import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;import java.io.IOException;public class Log4JException { private static final Logger LOGGER = LogManager.getLogger(Log4JException.class); public static void main(String args) { try { throw new IOException("This is an I/O error"); } catch (IOException ioe) { LOGGER.error("Error while executing main thread", ioe); } }}
Som du kan se, har vi denne gang inkluderet selve undtagelsesobjektet i vores logmeddelelse:
LOGGER.error("Error while executing main thread", ioe);
Det ville resultere i følgende fejllog i konsollen med vores standardkonfiguration:
11:30:17.527 ERROR - Error while executing main threadjava.io.IOException: This is an I/O error at com.sematext.blog.logging.Log4JException.main(Log4JException.java:13)
Den indeholder relevante oplysninger – i.dvs. navnet på klassen, den metode, hvor problemet opstod, og endelig linjenummeret, hvor problemet opstod. I virkelige situationer vil staksporene naturligvis være længere, men du bør medtage dem for at give dig nok oplysninger til korrekt fejlfinding.
For at få mere at vide om, hvordan du håndterer Java stakspor med Logstash, se Håndtering af stakspor med flere linjer med Logstash eller se på Logagent, som kan gøre det for dig out of the box.
Logging Java Exceptions
Når du håndterer Java-exceptions og stack traces skal du ikke kun tænke på hele stack trace’et, de linjer, hvor problemet optrådte osv. Du bør også tænke på, hvordan du ikke skal håndtere undtagelser.
Undgå at ignorere undtagelser i stilhed. Du ønsker ikke at ignorere noget vigtigt. Gør f.eks. ikke dette:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) {}
Lad dig heller ikke bare logge en undtagelse og smide den videre. Det betyder, at du bare har skubbet problemet op ad eksekveringsstakken. Undgå også ting som dette:
try { throw new IOException("This is an I/O error");} catch (IOException ioe) { LOGGER.error("I/O error occurred during request processing", ioe); throw ioe;}
Hvis du er interesseret i at lære mere om undtagelser, kan du læse vores guide om håndtering af undtagelser i Java, hvor vi dækker alt fra hvad de er til hvordan du fanger og retter dem.
Brug passende logniveau
Når du skriver din programkode, skal du tænke dig om en ekstra gang over en given logmeddelelse. Ikke alle oplysninger er lige vigtige, og ikke alle uventede situationer er en fejl eller en kritisk meddelelse. Brug også logningsniveauerne konsekvent – oplysninger af samme type bør være på samme sværhedsgrad.
Både SLF4J-facade og hver enkelt Java-logningsramme, som du vil bruge, indeholder metoder, der kan bruges til at angive et passende logningsniveau. For eksempel:
LOGGER.error("I/O error occurred during request processing", ioe);
Log i JSON
Hvis vi planlægger at logge og se på dataene manuelt i en fil eller i standardudgangen, vil den planlagte logning være mere end fin. Det er mere brugervenligt – vi er vant til det. Men det er kun levedygtigt for meget små applikationer, og selv da foreslås det at bruge noget, der giver dig mulighed for at korrelere metrikdataene med logfilerne. At udføre sådanne operationer i et terminalvindue er ikke sjovt, og nogle gange er det simpelthen ikke muligt. Hvis du ønsker at gemme logs i loghåndterings- og centraliseringssystemet skal du logge i JSON. Det skyldes, at parsing ikke er gratis – det betyder normalt, at du skal bruge regulære udtryk. Selvfølgelig kan du betale den pris i log-shipperen, men hvorfor gøre det, hvis du nemt kan logge i JSON. Logning i JSON betyder også nem håndtering af stack traces, så endnu en fordel. Nå, du kan også bare logge til en Syslog-kompatibel destination, men det er en anden historie.
I de fleste tilfælde er det nok at inkludere den rette konfiguration for at aktivere logning i JSON i dit Java logging framework. Lad os for eksempel antage, at vi har følgende logmeddelelse inkluderet i vores kode:
LOGGER.info("This is a log message that will be logged in JSON!");
For at konfigurere Log4J 2 til at skrive logmeddelelser i JSON skal vi inkludere følgende konfiguration:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <JSONLayout compact="true" eventEol="true"> </JSONLayout> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Resultatet ville se således ud:
{"instant":{"epochSecond":1596030628,"nanoOfSecond":695758000},"thread":"main","level":"INFO","loggerName":"com.sematext.blog.logging.Log4J2JSON","message":"This is a log message that will be logged in JSON!","endOfBatch":false,"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger","threadId":1,"threadPriority":5}
Hold logstrukturen konsistent
Strukturen af dine logbegivenheder skal være konsistent. Dette gælder ikke kun inden for et enkelt program eller et sæt mikrotjenester, men bør anvendes på tværs af hele din programstakke. Med loghændelser, der er struktureret på samme måde, vil det være lettere at se på dem, sammenligne dem, korrelere dem eller blot gemme dem i et dedikeret datalager. Det er lettere at se på data, der kommer fra dine systemer, når du ved, at de har fælles felter som f.eks. sværhedsgrad og værtsnavn, så du nemt kan skære dataene ud i tern ud fra disse oplysninger. For inspiration kan du tage et kig på Sematext Common Schema, selv om du ikke er Sematext-bruger.
Det er selvfølgelig ikke altid muligt at holde strukturen, fordi din fulde stak består af eksternt udviklede servere, databaser, søgemaskiner, køer osv. som hver især har deres eget sæt af logs og logformater. Men for at holde din og dit teams fornuftighed minimere antallet af forskellige logmeddelelsesstrukturer, som du kan kontrollere.
En måde at holde en fælles struktur på er at bruge det samme mønster for dine logs, i det mindste dem, der bruger den samme logningsramme. Hvis dine applikationer og mikroservices f.eks. bruger Log4J 2, kan du bruge et mønster som dette:
<PatternLayout> <Pattern>%d %p %c{35}:%L - %m%n</Pattern></PatternLayout>
Gennem at bruge et enkelt eller et meget begrænset sæt mønstre kan du være sikker på, at antallet af logformater forbliver lille og overskueligt.
Føj kontekst til dine logs
Informationskontekst er vigtig, og for os udviklere og DevOps er en logmeddelelse information. Se på følgende logpost:
An error occurred!
Vi ved, at der opstod en fejl et sted i programmet. Vi ved ikke, hvor den er opstået, vi ved ikke, hvilken slags fejl det var, vi ved kun, hvornår den er opstået. Se nu på en meddelelse med lidt flere kontekstuelle oplysninger:
com.sematext.blog.logging.ParsingErrorExample - A parsing error occurred for user with id 1234!
Den samme logpost, men med meget flere kontekstuelle oplysninger. Vi kender den tråd, hvor det skete, og vi ved, hvilken klasse fejlen blev genereret på. Vi har også ændret meddelelsen, så den indeholder den bruger, som fejlen er opstået for, så vi kan vende tilbage til brugeren, hvis det er nødvendigt. Vi kunne også inkludere yderligere oplysninger som f.eks. diagnostiske kontekster. Tænk over, hvad du har brug for, og inkluder det.
For at inkludere kontekstoplysninger behøver du ikke at gøre meget, når det gælder den kode, der er ansvarlig for at generere logmeddelelsen. For eksempel giver PatternLayout i Log4J 2 dig alt det, du har brug for, for at inkludere kontekstoplysningerne. Du kan gå med et meget simpelt mønster som dette:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
Det vil resultere i en logmeddelelse, der ligner den følgende:
17:13:08.059 INFO - This is the first INFO level log message!
Men du kan også inkludere et mønster, der vil indeholde langt flere oplysninger:
<PatternLayout pattern="%d{HH:mm:ss.SSS} %c %l %-5level - %msg%n"/>
Det vil resultere i en logmeddelelse som denne:
17:24:01.710 com.sematext.blog.logging.Log4j2 com.sematext.blog.logging.Log4j2.main(Log4j2.java:12) INFO - This is the first INFO level log message!
Java Logging in Containers
Tænk på det miljø, som dit program skal køre i. Der er forskel på logføringskonfigurationen, når du kører din Java-kode i en VM eller på en bare-metal-maskine, det er anderledes, når du kører den i et containeriseret miljø, og det er naturligvis anderledes, når du kører din Java- eller Kotlin-kode på en Android-enhed.
For at konfigurere logføring i et containeriseret miljø skal du vælge den fremgangsmåde, du ønsker at benytte. Du kan bruge en af de medfølgende logningsdrivere – som journald, logagent, Syslog eller JSON-fil. For at gøre det skal du huske, at dit program ikke skal skrive logfilen til containerens flygtige lager, men til standardudgangen. Det kan nemt gøres ved at konfigurere din logningsramme til at skrive logfilen til konsollen. Med Log4J 2 skal du f.eks. blot bruge følgende appender-konfiguration:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %m %n"/> </Console></Appenders>
Du kan også helt udelade logging-driverne og sende logs direkte til din centraliserede logs-løsning som f.eks. vores Sematext Cloud:
<Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d %level %c - %m%n"/> </Console> <Syslog name="Syslog" host="logsene-syslog-receiver.sematext.com" port="514" protocol="TCP" format="RFC5424" appName="11111111-2222-3333-4444-555555555555" facility="LOCAL0" mdcId="mdc" newLine="true"/></Appenders>
Log ikke for meget eller for lidt
Som udviklere har vi en tendens til at tro, at alt kan være vigtigt – vi har en tendens til at markere hvert trin i vores algoritme eller forretningskode som vigtigt. På den anden side gør vi nogle gange det modsatte – vi tilføjer ikke logning, hvor vi burde, eller vi logger kun FATAL- og ERROR-logniveauerne. Begge tilgange vil ikke fungere særlig godt. Når du skriver din kode og tilføjer logning, skal du tænke på, hvad der vil være vigtigt for at se, om programmet fungerer korrekt, og hvad der vil være vigtigt for at kunne diagnosticere en forkert programtilstand og rette den. Brug dette som din rettesnor for at beslutte, hvad og hvor der skal logges. Husk på, at tilføjelse af for mange logs vil ende med informationstræthed, og ikke at have nok information vil resultere i manglende evne til fejlfinding.
Hold publikum i tankerne
I de fleste tilfælde vil du ikke være den eneste person, der kigger på logs. Husk altid på det. Der er flere aktører, der kan kigge på logfilerne.
Den udvikler kan kigge på logfilerne i forbindelse med fejlfinding eller under debugging-sessioner. For sådanne personer kan logfilerne være detaljerede, tekniske og indeholde meget dybe oplysninger om, hvordan systemet kører. En sådan person vil også have adgang til koden eller vil endda kende koden, og det kan du gå ud fra.
Så er der DevOps. For dem vil logbegivenheder være nødvendige til fejlfinding og bør indeholde oplysninger, der er nyttige i forbindelse med diagnosticering. Du kan antage viden om systemet, dets arkitektur, dets komponenter og konfigurationen af komponenterne, men du bør ikke antage viden om platformens kode.
Endeligt kan dine programlogs læses af dine brugere selv. I et sådant tilfælde skal logfilerne være beskrivende nok til at hjælpe med at løse problemet, hvis det overhovedet er muligt, eller give tilstrækkelige oplysninger til det supportteam, der hjælper brugeren. Hvis du f.eks. bruger Sematext til overvågning, skal du installere og køre en overvågningsagent. Hvis du befinder dig bag en meget restriktiv firewall, og agenten ikke kan sende metrikker til Sematext, logger den fejl målrettet, som Sematext-brugerne selv også kan se på.
Vi kunne gå videre og identificere endnu flere aktører, der kan kigge i logfiler, men denne liste bør give dig et indblik i, hvad du bør tænke på, når du skriver dine logmeddelelser.
Undergå logning af følsomme oplysninger
Følsomme oplysninger bør ikke være til stede i logfiler eller bør maskeres. Adgangskoder, kreditkortnumre, socialsikringsnumre, adgangstokens og så videre – alt dette kan være farligt, hvis det lækkes eller tilgås af personer, der ikke bør se det. Der er to ting, du bør overveje.
Tænk over, om følsomme oplysninger virkelig er vigtige for fejlfinding. Måske er det i stedet for et kreditkortnummer nok at opbevare oplysninger om transaktionsidentifikator og transaktionsdatoen? Måske er det ikke nødvendigt at opbevare socialsikringsnummeret i logfilerne, når du nemt kan gemme brugeridentifikatoren. Tænk over sådanne situationer, tænk over de data, du gemmer, og skriv kun følsomme data, når det virkelig er nødvendigt.
Den anden ting er at sende logs med følsomme oplysninger til en hosted logs-tjeneste. Der er meget få undtagelser, hvor følgende råd ikke bør følges. Hvis dine logfiler har og skal have lagret følsomme oplysninger, skal du maskere eller fjerne dem, før du sender dem til dit centraliserede logfillager. De fleste populære log-shippere, som f.eks. vores egen Logagent, indeholder funktionalitet, der gør det muligt at fjerne eller maskere følsomme data.
Endeligt kan maskering af følsomme oplysninger foretages i selve logningsrammen. Lad os se på, hvordan det kan gøres ved at udvide Log4j 2. Vores kode, der producerer logbegivenheder, ser således ud (det fulde eksempel kan findes på Sematext Github):
public class Log4J2Masking { private static Logger LOGGER = LoggerFactory.getLogger(Log4J2Masking.class); private static final Marker SENSITIVE_DATA_MARKER = MarkerFactory.getMarker("SENSITIVE_DATA_MARKER"); public static void main(String args) { LOGGER.info("This is a log message without sensitive data"); LOGGER.info(SENSITIVE_DATA_MARKER, "This is a a log message with credit card number 1234-4444-3333-1111 in it"); }}
Hvis du skulle køre hele eksemplet fra Github ville output være som følger:
21:20:42.099 - This is a log message without sensitive data21:20:42.101 - This is a a log message with credit card number ****-****-****-**** in it
Du kan se, at kreditkortnummeret blev maskeret. Dette blev gjort, fordi vi tilføjede en brugerdefineret konverter, der kontrollerer, om den givne markør er videregivet langs logbegivenheden og forsøger at erstatte et defineret mønster. Implementeringen af en sådan Converter ser således ud:
@Plugin(name = "sample_logging_mask", category = "Converter")@ConverterKeys("sc")public class LoggingConverter extends LogEventPatternConverter { private static Pattern PATTERN = Pattern.compile("\b({4})-({4})-({4})-({4})\b"); public LoggingConverter(String options) { super("sc", "sc"); } public static LoggingConverter newInstance(final String options) { return new LoggingConverter(options); } @Override public void format(LogEvent event, StringBuilder toAppendTo) { String message = event.getMessage().getFormattedMessage(); String maskedMessage = message; if (event.getMarker() != null && "SENSITIVE_DATA_MARKER".compareToIgnoreCase(event.getMarker().getName()) == 0) { Matcher matcher = PATTERN.matcher(message); if (matcher.find()) { maskedMessage = matcher.replaceAll("****-****-****-****"); } } toAppendTo.append(maskedMessage); }}
Det er meget simpelt og kunne skrives på en mere optimeret måde og skulle også kunne håndtere alle mulige kreditkortnummerformater, men det er nok til dette formål.
Hvor vi hopper ind i kodeforklaringen, vil jeg også gerne vise dig log4j2.xml-konfigurationsfilen for dette eksempel:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="WARN" packages="com.sematext.blog.logging"> <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} - %sc %n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> </Loggers></Configuration>
Som du kan se, har vi tilføjet attributen packages i vores Configuration for at fortælle rammen, hvor den skal lede efter vores konverter. Derefter har vi brugt %sc-mønstret til at angive logmeddelelsen. Det gør vi, fordi vi ikke kan overskrive standardmønsteret %m-mønsteret. Når Log4j2 finder vores %sc-mønster, vil den bruge vores konverter, som tager den formaterede meddelelse fra logbegivenheden og bruger en simpel regex og erstatter dataene, hvis den blev fundet. Så enkelt er det.
En ting, der skal bemærkes her, er, at vi bruger Marker-funktionaliteten. Regex-matching er dyrt, og vi ønsker ikke at gøre det for hver logmeddelelse. Derfor markerer vi de logbegivenheder, der skal behandles, med den oprettede Marker, så kun de markerede kontrolleres.
Brug en loghåndteringsløsning til at centralisere & Overvåg Java-logs
Med programmernes kompleksitet vokser mængden af dine logs også. Du kan slippe af sted med at logge til en fil og kun bruge logfiler, når der er behov for fejlfinding, men når mængden af data vokser, bliver det hurtigt vanskeligt og langsomt at foretage fejlfinding på denne måde Når dette sker, skal du overveje at bruge en loghåndteringsløsning til at centralisere og overvåge dine logfiler. Du kan enten vælge en intern løsning baseret på open source-software som Elastic Stack eller bruge et af de loghåndteringsværktøjer, der findes på markedet som Sematext Logs.
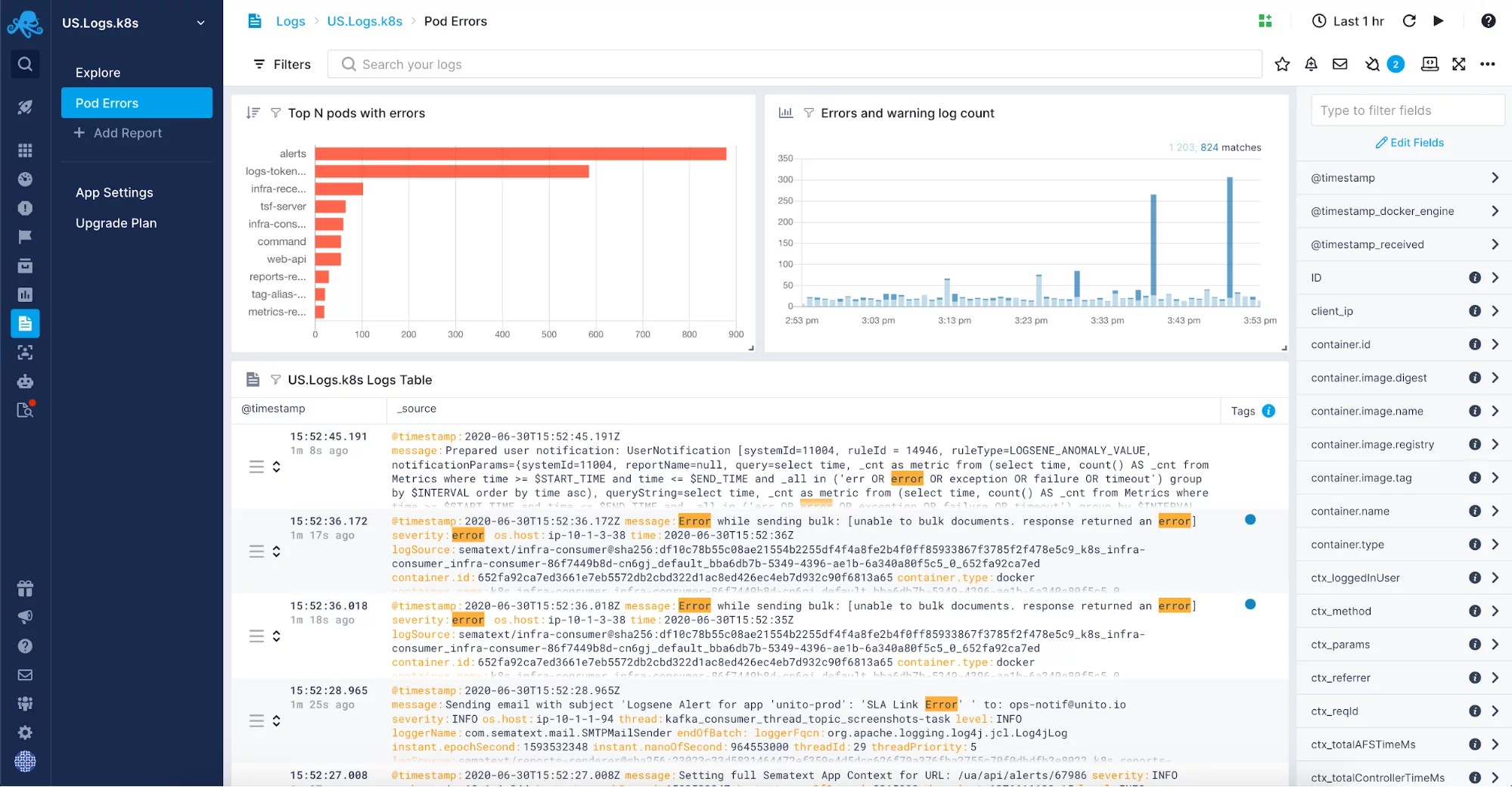
En fuldt administreret logcentraliseringsløsning vil give dig den frihed, at du ikke behøver at administrere endnu en, normalt ret kompleks, del af din infrastruktur. I stedet vil du kunne fokusere på din applikation og behøver kun at opsætte logforsendelse. Du ønsker måske at inkludere logs som JVM garbage collection-logs i din managed log-løsning. Når du har slået dem til for dine programmer og systemer, der arbejder på JVM’en, vil du gerne samle logs et enkelt sted med henblik på logkorrelation, loganalyse og for at hjælpe dig med at indstille garbage collection i JVM-instanserne. Sådanne logs korreleret med metrikker er en uvurderlig informationskilde til fejlfinding af garbage collection-relaterede problemer.
Hvis du er interesseret i at se, hvordan Sematext Logs klarer sig i forhold til lignende løsninger, kan du gå til vores artikel om den bedste loghåndteringssoftware eller blogindlægget, hvor vi gennemgår nogle af de bedste loganalyseværktøjer, men vi anbefaler, at du bruger den 14-dages gratis prøveperiode for at udforske dens funktioner fuldt ud. Prøv det og se selv!
Konklusion
Indarbejdelse af hver eneste god praksis er måske ikke let at implementere med det samme, især ikke for applikationer, der allerede er live og arbejder i produktion. Men hvis du tager dig tid og udruller forslagene et efter et, vil du begynde at se en stigning i anvendeligheden af dine logs. Hvis du vil have flere tips til, hvordan du får mest muligt ud af dine logs, anbefaler vi, at du også gennemgår vores anden artikel om logging best practices, hvor vi forklarer og ins and outs du bør følge uanset hvilken type app du arbejder med. Og husk, at vi hos Sematext hjælper organisationer med deres logningsopsætning ved at tilbyde logningsrådgivning, så tag fat i os, hvis du har problemer, så hjælper vi dig gerne.
Skriv et svar