Afmeld dig til vores daglige referater af det stadigt skiftende søgemarkedsføringslandskab.
Bemærk: Ved at indsende denne formular accepterer du Third Door Medias vilkår. Vi respekterer dit privatliv.

På internetfora og indholdsrelaterede Facebook-grupper bryder der ofte diskussioner ud om, hvordan Googlebot fungerer – som vi her nænsomt vil kalde GB – og hvad den kan se og ikke kan se, hvilke links den besøger, og hvordan den påvirker SEO.
I denne artikel vil jeg præsentere resultaterne af mit tre måneder lange eksperiment.
Næsten dagligt i de sidste tre måneder har GB besøgt mig som en ven, der kommer forbi til en øl.
I nogle tilfælde var den alene:
: 66.249.76.136 /page1.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.136 /page5.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.76.140 /page3.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page2.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
: 66.249.64.72 /page6.html Mozilla/5.0 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
Sommetider har den taget sine venner med:
: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, ligesom Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
: 66.249.69.235 /image.jpg Googlebot-Image/1.0
: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, som Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html)
Og vi havde masser af sjov med at spille forskellige spil:
Catch: Jeg observerede, hvordan GB elsker at køre omdirigeringer 301 og crawle billeder og køre fra canonicals.
Gemmeleg: Googlebot gemte sig i det skjulte indhold (som den, som dens forældre hævder, ikke tolererer og undgår)
Survival: Jeg forberedte fælder og ventede på, at den ville springe dem ud.
Hindringer: Jeg placerede forhindringer med forskellige sværhedsgrader for at se, hvordan min lille ven ville klare dem.
Som du sikkert kan se, blev jeg ikke skuffet. Vi havde masser af sjov, og vi blev gode venner. Jeg tror, at vores venskab har en lys fremtid.
Men lad os komme til sagen!
Jeg byggede et websted med meritter-relateret indhold om et interstellært rejsebureau, der tilbyder flyvninger til endnu uopdagede planeter i vores galakse og længere væk.
Indholdet så ud til at have en masse meritter, mens det i virkeligheden var en masse vrøvl.
Strukturen af det eksperimentelle websted så således ud:
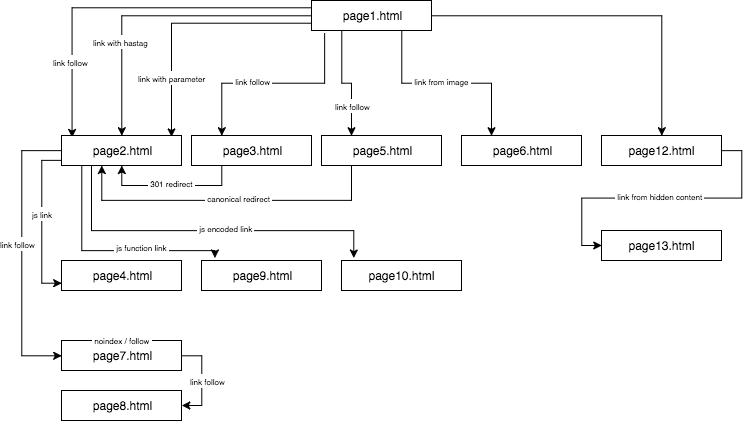
Jeg leverede unikt indhold og sørgede for, at hvert anker/titel/alt samt andre koefficienter var globalt unikke (falske ord). For at gøre det lettere for læseren vil jeg i beskrivelsen ikke bruge navne som anker cutroicano matestito, men i stedet henvise til dem som anker1 osv.
Jeg foreslår, at du holder ovenstående kort åbent i et separat vindue, mens du læser denne artikel.
- Del 1: Første link tæller
- Link til et websted med et anker
- Link til et websted med en parameter
- Link til et websted fra en omdirigering
- Link til en side ved hjælp af canonical tag
- Del 2: Crawl-budget
- JavaScript-link med en onclick-hændelse
- Javascript-link med en intern funktion
- JavaScript-link med kodning
- Del 3: Skjult indhold
- Om forfatteren
Del 1: Første link tæller
En af de ting, som jeg ville teste i dette SEO-eksperiment, var reglen om første link tæller – om den kan udelades, og hvordan den påvirker optimeringen.
Reglen om første link tæller siger, at på en side ser Google Bot kun det første link til en underside. Hvis du har to links til den samme underside på en side, vil det andet link blive ignoreret i henhold til denne regel. Google Bot vil ignorere ankeret i det andet og i hvert efterfølgende link, mens han beregner sidens rang.
Det er et problem, som mange specialister ser bredt på, men som især er til stede i onlinebutikker, hvor navigationsmenuer forvrænger hjemmesidens struktur betydeligt.
I de fleste butikker har vi en statisk (synlig i sidens kilde) drop-down menu, som f.eks. giver fire links til hovedkategorier og 25 skjulte links til underkategorier. Under kortlægningen af en sides struktur ser GB alle links (på hver side med menu), hvilket resulterer i, at alle siderne har lige stor betydning under kortlægningen, og deres kraft (juice) fordeles jævnt, hvilket ser nogenlunde sådan ud:
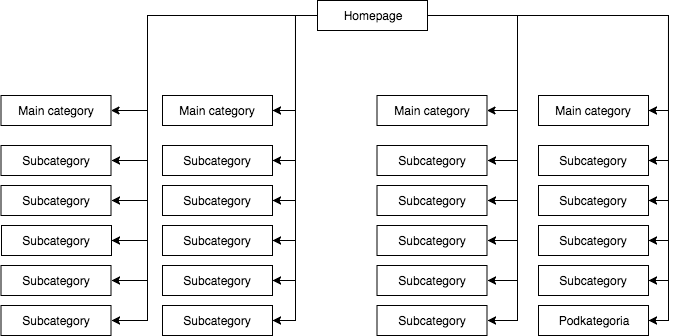
Den mest almindelige, men efter min mening forkerte sidestruktur.
Overstående eksempel kan ikke kaldes en ordentlig struktur, da alle kategorierne er linket fra alle de sider, hvor der er en menu. Derfor har både forsiden og alle kategorier og underkategorier lige mange indgående links, og hele webtjenestens kraft flyder gennem dem med lige stor styrke. Derfor bliver kraften fra hjemmesiden (som normalt er kilden til størstedelen af kraften på grund af antallet af indgående links) fordelt på 24 kategorier og underkategorier, så hver af dem modtager kun 4 % af kraften fra hjemmesiden.
Sådan bør strukturen se ud:

Hvis du har brug for hurtigt at teste strukturen på din side og crawle den som Google gør, er Screaming Frog et nyttigt værktøj.
I dette eksempel er hjemmesidens power delt op i fire, og hver af kategorierne modtager 25 procent af hjemmesidens power og fordeler en del af den til underkategorierne. Denne løsning giver også en bedre chance for intern linking. Når du f.eks. skriver en artikel på butikkens blog og ønsker at linke til en af underkategorierne, vil GB lægge mærke til linket, når GB crawler hjemmesiden. I det første tilfælde vil den ikke gøre det på grund af reglen om, at det første link tæller. Hvis linket til en underkategori var i hjemmesidens menu, vil linket i artiklen blive ignoreret.
Jeg startede dette SEO-eksperiment med følgende handlinger:
- Først, på siden1.html inkluderede jeg et link til en underside page2.html som et klassisk dofollow-link med et anker: anchor1.
- Dernæst inkluderede jeg i teksten på samme side let ændrede henvisninger for at verificere, om GB ville være ivrig efter at crawle dem.
Dertil testede jeg følgende løsninger:
- Til webtjenestens hjemmeside tildelte jeg ét eksternt dofollow-link til en sætning med et URL-anker (så enhver ekstern linkning af hjemmesiden og undersiderne for givne sætninger var udelukket) – det fremskyndede indekseringen af tjenesten.
- Jeg ventede på, at side2.html begyndte at rangere for en sætning fra det første dofollow-link (anker1), der kom fra side1.html. Denne falske sætning, eller nogen anden, som jeg testede, kunne ikke findes på målesiden. Jeg antog, at hvis andre links ville virke, så ville page2.html også ranke i søgeresultaterne for andre sætninger fra andre links. Det tog omkring 45 dage. Og så kunne jeg drage den første vigtige konklusion:
Selv et websted, hvor et nøgleord hverken er i indholdet eller i metatitlen, men er knyttet med et undersøgt anker, kan sagtens ranke højere i søgeresultaterne end et websted, der indeholder dette ord, men som ikke er knyttet til et nøgleord.
Dertil kommer, at hjemmesiden (page1.html), som indeholdt den undersøgte sætning, var den stærkeste side i webtjenesten (linket fra 78 procent af undersiderne), og alligevel rangerede den lavere på den undersøgte sætning end undersiden (page2.html), der var linket til den undersøgte sætning.
Nedenfor præsenterer jeg fire typer af links, som jeg har testet, og som alle kommer efter det første dofollow-link, der fører til page2.html.
Link til et websted med et anker
< a href=”page2.html#testhash” >anker2< /a >
Det første af de yderligere links, der kommer i koden bag dofollow-linket, var et link med et anker (et hashtag). Jeg ville se, om GB ville gå igennem linket og også indeksere side2.html under sætningen anchor2, på trods af at linket fører til denne side (side2.html), men at URL’en bliver ændret til side2.html#testhash bruger anchor2.
Uheldigvis ville GB aldrig huske denne forbindelse, og den ledte ikke kraften til undersiden side2.html for denne sætning. Resultatet er, at der i søgeresultaterne for sætningen anchor2 på den dag, hvor denne artikel skrives, kun findes undersiden page1.html, hvor ordet findes i linkets anker. Når man googler på sætningen testhash, rangerer vores domæne heller ikke.
Link til et websted med en parameter
page2.html?parameter=1
I første omgang var GB interesseret i denne sjove del af URL’en lige efter forespørgselsmærket og ankeret inde i anker3-linket.
Interesseret forsøgte GB at regne ud, hvad jeg mente. Den tænkte: “Er det en gåde?” For at undgå at indeksere det dobbelte indhold under de andre URL’er pegede den kanoniske page2.html på sig selv. Logfilerne registrerede i alt 8 crawls på denne adresse, men konklusionerne var ret triste:
- Efter 2 uger faldt frekvensen af GB’s besøg betydeligt, indtil den til sidst forlod stedet og aldrig crawlede dette link igen.
- page2.html blev ikke indekseret under sætningen anchor3, og det blev heller ikke parameteren med URL-parameter1. Ifølge Search Console eksisterer dette link ikke (det tælles ikke med blandt indgående links), men samtidig er sætningen anchor3 opført som en forankret sætning.
Link til et websted fra en omdirigering
Jeg ønskede at tvinge GB til at crawle mit websted mere, hvilket resulterede i, at GB med et par dages mellemrum indtastede dofollow-linket med et anker anchor4 på page1.html, der fører til page3.html, som omdirigerer med en 301-kode til page2.html. Desværre var side2.html, ligesom i tilfældet med siden med en parameter, efter 45 dage endnu ikke rangeret i søgeresultaterne for den anker4-frase, der optrådte i det omdirigerede link på side1.html.
Men i Google Search Console, i afsnittet Ankertekster, er anker4 dog synlig og indekseret. Det kunne tyde på, at omdirigeringen efter et stykke tid begynder at fungere som forventet, så side2.html rangerer i søgeresultaterne for anker4 på trods af, at det er det andet link til den samme målside på det samme websted.
Link til en side ved hjælp af canonical tag
På side1.html har jeg placeret en henvisning til side5.html (follow link) med et anker anchor5. Samtidig var der på side5.html et unikt indhold, og i dets hoved var der et canonical tag til side2.html.
< link rel=”canonical” href=”https://example.com/page2.html” />
Denne test gav følgende resultater:
- Linket til anker5-frasen, der henviser til side5.html, omdirigerer kanonisk til side2.html blev ikke overført til målesiden (ligesom i de andre tilfælde).
- page5.html blev indekseret på trods af det kanoniske tag.
- page5.html blev ikke placeret i søgeresultaterne for anker5.
- page5.html rangerede på de sætninger, der blev brugt i sidens tekst, hvilket indikerede, at GB fuldstændig ignorerede de kanoniske tags.
Jeg vil vove at påstå, at det simpelthen ikke kunne fungere at bruge rel=canonical til at forhindre indeksering af noget indhold (f.eks. under filtrering).
Del 2: Crawl-budget
Ved udformningen af en SEO-strategi ønskede jeg at få GB til at danse efter min melodi og ikke omvendt. Til dette formål verificerede jeg SEO-processerne på niveauet af serverlogfilerne (adgangslogfiler og fejllogfiler), hvilket gav mig en stor fordel. Takket være det kendte jeg GB’s hver eneste bevægelse, og hvordan den reagerede på de ændringer, jeg indførte (omstrukturering af webstedet, vending af det interne linksystem på hovedet, måden at vise oplysninger på) inden for rammerne af SEO-kampagnen.
En af mine opgaver under SEO-kampagnen var at genopbygge et websted på en måde, der ville få GB til kun at besøge de URL’er, som den kunne indeksere, og som vi ønskede, at den skulle indeksere. Kort sagt: Der skulle kun være de sider, som er vigtige for os ud fra et SEO-synspunkt, i Googles indeks. På den anden side bør GB kun crawle de websteder, som vi ønsker at blive indekseret af Google, hvilket ikke er indlysende for alle, f.eks. når en netbutik implementerer filtrering efter farver, størrelse og priser, og det sker ved at manipulere URL-parametrene, f.eks.:
eksempel.com/kvinder/sko/?color=red&size=40&size=40&price=200-250
Det kan vise sig, at en løsning, der giver GB mulighed for at crawle dynamiske URL’er, gør, at den bruger tid på at gennemsøge (og eventuelt indeksere) dem i stedet for at crawle siden.
eksempel.com/women/shoes/
Sådanne dynamisk oprettede URL’er er ikke kun ubrugelige, men potentielt skadelige for SEO, fordi de kan forveksles med tyndt indhold, hvilket vil resultere i et fald i hjemmesidens placeringer.
I dette eksperiment ønskede jeg også at kontrollere nogle metoder til strukturering uden at bruge rel=”nofollow”, blokere GB i robots.txt-filen eller placere en del af HTML-koden i rammer, der er usynlige for botten (blokeret iframe).
Jeg testede tre slags JavaScript-links.
JavaScript-link med en onclick-hændelse
Et simpelt link konstrueret på JavaScript
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html'” >anchor6< /a >
GB gik let videre til undersiden page4.html og indekserede hele siden. Undersiden rangerer ikke i søgeresultaterne for sætningen anchor6, og denne sætning kan ikke findes i afsnittet Ankertekster i Google Search Console. Konklusionen er, at linket ikke overførte juice.
For at opsummere:
- Et klassisk JavaScript-link giver Google mulighed for at crawle webstedet og indeksere de sider, det kommer på.
- Det overfører ikke juice – det er neutralt.
Javascript-link med en intern funktion
Jeg besluttede mig for at hæve spillet, men til min overraskelse overvandt GB forhindringen på mindre end 2 timer efter offentliggørelsen af linket.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
For at betjene dette link brugte jeg en ekstern funktion, som havde til formål at læse URL’en fra dataene og omdirigering – kun omdirigering af en bruger, som jeg håbede – til målet page9.html. Som i det tidligere tilfælde var side9.html blevet fuldt indekseret.
Det interessante er, at på trods af manglen på andre indgående links var side9.html den tredje mest besøgte side af GB i hele webtjenesten, lige efter side1.html og side2.html.
Jeg havde brugt denne metode før til strukturering af webtjenester. Men som vi kan se, virker den ikke længere. Inden for SEO er der intet, der lever for evigt, bortset fra de gule sider.
JavaScript-link med kodning
Selvfølgelig ville jeg ikke give op, og jeg besluttede mig for, at der måtte være en måde at lukke døren effektivt i hovedet på GB. Så jeg konstruerede en simpel funktion og kodede dataene med en base64-algoritme, og referencen så således ud:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
Som følge heraf var GB ikke i stand til at fremstille en JavaScript-kode, der både kunne afkode indholdet af en data-URL-attribut og viderestille. Og der var det så! Vi har en måde at strukturere en webtjeneste på uden at bruge rel=nonfollows for at forhindre bots i at crawle, hvor de vil! På den måde spilder vi ikke vores crawl-budget, hvilket især er vigtigt i forbindelse med store webtjenester, og GB danser endelig efter vores melodi. Uanset om funktionen blev indført på samme side i head-sektionen eller i en ekstern JS-fil, er der ingen tegn på en bot, hverken i serverlogfilerne eller i Search Console.
Del 3: Skjult indhold
I den sidste test ville jeg undersøge, om indholdet i f.eks. skjulte faner ville blive taget i betragtning og indekseret af GB, eller om Google renderede en sådan side og ignorerede den skjulte tekst, som nogle specialister har hævdet.
Jeg ville enten bekræfte eller afvise denne påstand. For at gøre det placerede jeg en væg af tekst med over 2000 tegn på side12.html og skjulte en tekstblok med ca. 20 procent af teksten (400 tegn) i Cascading Style Sheets, og jeg tilføjede knappen show more (vis mere). Inden for den skjulte tekst var der et link til side13.html med et anker anchor9.
Der er ingen tvivl om, at en bot kan rendere en side. Vi kan observere det i både Google Search Console og Google Insight Speed. Ikke desto mindre viste mine tests, at en tekstblok, der blev vist efter at have klikket på knappen vis mere, blev fuldt indekseret. De sætninger, der var skjult i teksten, rangerede i søgeresultaterne, og GB fulgte de links, der var skjult i teksten. Desuden var anklerne på linkene fra en skjult tekstblok synlige i Google Search Console i afsnittet Ankertekst, og page13.html begyndte også at ranke i søgeresultaterne for søgeordet anker9.
Dette er afgørende for netbutikker, hvor indholdet ofte er placeret i skjulte faner. Nu er vi sikre på, at GB ser indholdet i skjulte faner, indekserer dem og overfører juicen fra de links, der er skjult der.
Den vigtigste konklusion, som jeg drager af dette eksperiment, er, at jeg ikke har fundet en direkte måde at omgå reglen om, at det første link tæller, ved at bruge ændrede links (links med parameter, 301-omdirigeringer, canonicals, ankerlinks). Samtidig er det muligt at opbygge et websteds struktur ved hjælp af Javascript-links, takket være hvilke vi er fri for de begrænsninger, der følger af First Link Counts Rule. Desuden kan Google Bot se og indeksere indhold, der er skjult i bogmærker, og den følger de links, der er skjult i dem.
Abonner på vores daglige opsamlinger af det stadigt skiftende søgemarkedsføringslandskab.
Bemærk: Ved at indsende denne formular accepterer du Third Door Medias vilkår. Vi respekterer dit privatliv.
Om forfatteren

“Du skal ikke acceptere ‘bare’ høj kvalitet. Det kan alle gøre. Hvis himlen er grænsen, så find en højere himmel.” Max Cyrek er CEO for Cyrek Digital, en digital marketingkonsulent og SEO-evangelist. I løbet af sin karriere har Max sammen med sit team på over 30 personer arbejdet med hundredvis af virksomheder og hjulpet dem med at få succes. Han har arbejdet med digital markedsføring i næsten ti år og har specialiseret sig i teknisk SEO og ledet succesfulde markedsføringsprojekter.
Skriv et svar