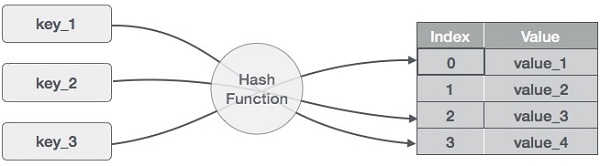
Hashtabellen er en datastruktur, der gemmer data på en associativ måde. I en hashtabel lagres data i et array-format, hvor hver dataværdi har sin egen unikke indeksværdi. Adgang til data bliver meget hurtig, hvis vi kender indekset for de ønskede data.
Det bliver således en datastruktur, hvor indsættelses- og søgeoperationer er meget hurtige uanset dataenes størrelse. Hash Table bruger et array som lagringsmedie og anvender hash-teknikken til at generere et indeks, hvor et element skal indsættes eller findes fra.
Hashing
Hashing er en teknik til at konvertere en række nøgleværdier til en række indekser i et array. Vi skal bruge modulo-operatoren til at få et område af nøgleværdier. Overvej et eksempel på en hashtabel af størrelse 20, og følgende elementer skal gemmes. Elementerne er i formatet (nøgle,værdi).
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.nr. | Nøgle | Hash | Array Indeks | |
|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | |
| 2 | 2 | 2 | 2 % 20 = 2 | 2 |
| 3 | 42 | 42 % 20 = 2 | 2 | |
| 4 | 4 | 4 % 20 = 4 | 4 | |
| 5 | 12 | 12 % 20 = 12 | 12 | |
| 6 | 14 | 14 % 20 = 14 | 14 | |
| 7 | 17 | 17 % 20 = 17 | 17 | |
| 8 | 13 | 13 % 20 = 13 | 13 | |
| 9 | 37 | 37 % 20 = 17 | 17 |
Linear Sondering
Som vi kan se, kan det ske, at hash-teknikken bruges til at skabe et allerede brugt indeks i arrayet. I et sådant tilfælde kan vi søge efter den næste tomme placering i arrayet ved at kigge ind i den næste celle, indtil vi finder en tom celle. Denne teknik kaldes lineær probing.
| Sr.nr. | Nøgle | Hash | Array Indeks | Efter lineær probning, Array Index | |
|---|---|---|---|---|---|
| 1 | 1 | 1 % 20 = 1 | 1 | 1 | 1 |
| 2 | 2 | 2 % 20 = 2 | 2 | 2 | |
| 3 | 42 | 42 % 20 = 2 | 2 | 3 | |
| 4 | 4 | 4 % 20 = 4 | 4 | 4 | |
| 5 | 12 | 12 % 20 = 12 | 12 | 12 | |
| 6 | 14 | 14 % 20 = 14 | 14 | 14 | |
| 7 | 17 | 17 % 20 = 17 | 17 | 17 | |
| 8 | 13 | 13 % 20 = 13 | 13 | 13 | 13 |
| 9 | 37 | 37 % 20 = 17 | 17 | 18 |
Grundlæggende operationer
Følgende er de grundlæggende primære operationer i en hashtabel.
-
Søgning – søger et element i et hashtabellen.
-
Indsætning – indsætter et element i et hashtabellen.
-
sletning – sletter et element fra et hashtabellen.
DataItem
Definer et dataelement med nogle data og en nøgle, på grundlag af hvilke der skal søges i en hashtabel.
struct DataItem { int data; int key;};
Hashmetode
Definér en hashmetode til beregning af hashkoden for dataelementets nøgle.
int hashCode(int key){ return key % SIZE;}
Søgningsoperation
Når der skal søges efter et element, beregnes hashkoden for den overgivne nøgle, og elementet lokaliseres ved hjælp af denne hashkode som indeks i arrayet. Brug lineær probing til at få elementet frem, hvis elementet ikke findes ved den beregnede hashkode.
Eksempel
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray != NULL) { if(hashArray->key == key) return hashArray; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Insert Operation
Når et element skal indsættes, beregnes hashkoden for den overgivne nøgle, og indekset lokaliseres ved hjælp af denne hashkode som indeks i arrayet. Brug lineær probing for tom placering, hvis der findes et element ved den beregnede hashkode.
Eksempel
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray != NULL && hashArray->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray = item; }
Slet operation
Når et element skal slettes, beregnes hashkoden for den overgivne nøgle, og indekset lokaliseres ved hjælp af denne hashkode som indeks i arrayet. Brug lineær probing til at få elementet frem, hvis der ikke findes et element ved den beregnede hashkode. Når det er fundet, lagres et dummy-element der for at holde hashtabellens ydeevne intakt.
Eksempel
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray !=NULL) { if(hashArray->key == key) { struct DataItem* temp = hashArray; //assign a dummy item at deleted position hashArray = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
For at vide mere om hash-implementering i programmeringssproget C skal du klikke her.
Skriv et svar